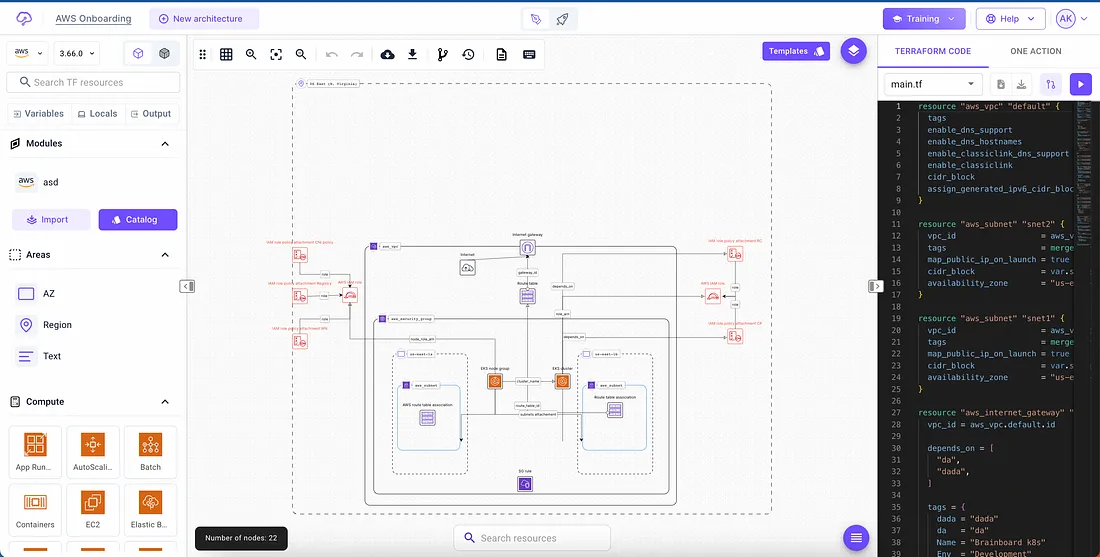
No mundo em constante evolução da computação em nuvem, o papel de um arquiteto de nuvem é fundamental. À medida que as empresas migram para a nuvem, a necessidade de uma infraestrutura robusta, escalável e segura torna-se fundamental.
Aqui estão 14 coisas essenciais que todo arquiteto de nuvem deve estar ciente antes de embarcar em um novo projeto de infraestrutura.
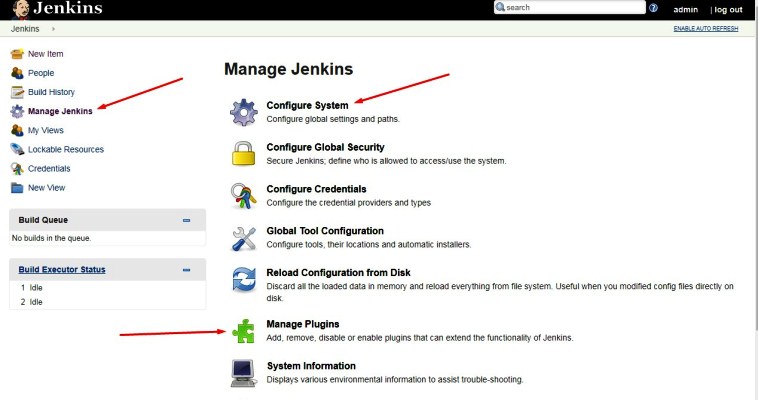
Função do arquiteto de nuvem no projeto de infraestrutura
Diagramas
Um arquiteto de nuvem deve sempre criar diagramas detalhados que mapeiem toda a infraestrutura, mostrando como os diferentes componentes interagem entre si.
Esses diagramas devem contemplar o mapeamento de rede, as rotas necessárias para garantir a comunicação dos componentes com todos os recursos necessários para o seu funcionamento, as regras de segurança que devem ser criadas, os fluxos de dados e toda a informação necessária para que a infraestrutura seja corretamente construída. A esse(s) diagrama(s) damos o nome de LLD (low level design).
Escala
O dimensionamento é um aspecto crítico da infraestrutura em nuvem. Os arquitetos de nuvem devem projetar sistemas que possam lidar com cargas de trabalho maiores sem comprometer o desempenho.
Testes de carga podem ser executados para determinar qual é a quantidade de requisições que a infraestrutura suporta, bem como quando ela começará a escalar seus recursos.
Manutenção
A manutenção envolve atualizações regulares, patches e garantia de que a infraestrutura esteja funcionando de maneira ideal. Um arquiteto de nuvem deve ser proativo na identificação de possíveis problemas e na solução imediata deles.
E agora, sem mais delongas, as
14 coisas que todo arquiteto de nuvem deveria conhecer
1 – Monitoramento de rede
Como engenheiros de nuvem, otimizar o monitoramento de rede é crucial. Ferramentas como VPC Flow Logs (AWS-GCP) e Azure Monitor (Azure) são inestimáveis para monitorar o tráfego de rede, detectar anomalias e solucionar problemas.
2 – Redundância e recuperação
É essencial lidar com o aumento das cargas de trabalho e garantir uma recuperação rápida. Plataformas como Amazon ECS, AKS ou GKE ajudam na alocação dinâmica de recursos e na garantia de alta disponibilidade e alta performance.
3 – Segurança
A segurança na nuvem não é negociável. Proteja recursos e dados usando AWS IAM, Azure AD e GCP IAM, grupos de segurança, firewalls como serviço e criptografia em trânsito e em repouso para evitar acesso não autorizado e vazamento de dados.
4 – Gerenciamento de custos
Os modelos de preço de provedores de nuvem tendem a ser complexos. A operação financeira da nuvem (FinOps) requer ferramentas como AWS Cost Explorer ou Azure Cost Management. Estratégias como redimensionar instâncias e automatizar o gerenciamento de recursos podem levar a economias de custos significativas. É importante trabalhar com ferramentas como Trusted Advisor da AWS e suas correlatas em outros provedores de nuvem ou com ferramentas agnósticas como CloudHealth.
5 – Governança
A governança da nuvem garante conformidade e segurança. Ferramentas como AWS Organizations, Azure Policy e GCP Resource Manager são essenciais para impor a conformidade e simplificar o gerenciamento.
6 – Otimização de desempenho
O ajuste fino dos bancos de dados e do cache com ferramentas como Amazon RDS, Amazon Elasticache ou Azure Cache for Redis, bem como a utilização de aceleradores de conteúdo (CDN) pode melhorar drasticamente a capacidade de resposta dos aplicativos.
7 – Recuperação de desastres
Ferramentas como AWS Disaster Recovery, Azure Site Recovery e GCP Cloud Deployment Manager são essenciais para replicação de dados e estabelecimento de configurações de failover. Durante as primeiras fases do projeto devem ser definidos com o cliente os dados de SLO, RPO e RTO.
8 – Gerenciamento de dados
Garanta a integridade e o desempenho dos dados usando Amazon S3, Azure Blob Storage ou Google Cloud Storage. Aborde técnicas de particionamento e fragmentação de dados para melhorar a escalabilidade e jamais esqueça-se da criptografia em repouso.
9 – Conformidade
A adesão aos padrões da indústria como a ISO 27001 é crucial. Implemente controles de acesso e criptografia para garantir a conformidade entre plataformas.
10 – Monitoramento e registro em logs
Ferramentas de monitoramento e de trilhas de registro e de auditoria como AWS CloudWatch, AWS CloudTrail, Azure Monitor ou Google Cloud Monitoring são vitais para verificações de integridade do sistema, identificação de ameaças e solução de problemas.
11 – Desenvolvimento de aplicativos nativos da nuvem
Os desenvolvedores devem sempre manter o foco em microsserviços, conteinerização e descoberta de serviços. Utilize AWS Fargate, AWS Lambda, EKS, AKS e Azure Functions e GKE para implantações escalonáveis e ferramentas como DynamoDB, Cosmos DB ou Google Cloud Spanner para armazenamento de dados. Abuse sem moderação dos serviços em nuvem.
12 – Edge computing e IoT
Gerenciar dispositivos de borda e lidar com a sincronização de dados é um desafio. Use o AWS IoT Core, o Azure IoT Hub e o Google Cloud IoT Core para um gerenciamento eficaz.
13 – Processamento e análise de dados
O maior patrimônio das empresas hoje são os dados, e eles são gerados em volumes muito grandes a cada segundo. Estruturas de big data são essenciais. Ferramentas como Amazon Redshift, Azure Synapse Analytics ou Google BigQuery, juntamente com AWS MSK, Azure Event Hubs ou GCP Pub/Sub, são cruciais para processamento e análise de dados em tempo real.
14 – Documentação
Uma documentação robusta e desenvolvida durante a criação da infraestrutura em nuvem é essencial não só como entregável para o cliente, mas para manter o conhecimento do projeto na empresa, de forma que qualquer outro arquiteto de nuvem possa melhorar a estrutura ou aprender com as boas práticas (e os erros cometidos) que usamos no projeto.
Concluindo, a função de um arquiteto de nuvem é multifacetada. Ao manter estes 14 pontos em mente, você pode garantir que os seus projetos de infraestruturas são robustos, escaláveis e seguros, satisfazendo as exigências cada vez maiores da era digital.
Terraform, da HashiCorp, é uma solução de Infrastructure as Code (IaC) que permite especificar configurações de infraestrutura, seja em cloud ou on-premise, em arquivos de configuração facilmente lidos por humanos, que podem ser reutilizados e compartilhados.
Muitos profissionais de TI atualmente utilizam Terraform para gerenciar sua infraestrutura. Mas, você sabia que há algumas melhore práticas que você deve seguir quando está escrevendo seus arquivos Terraform e definindo sua infraestrutura como código e seu workspace Terraform?
Este é um artigo mão na massa. Enquanto apresento as mais de 20 melhores práticas para Terraform, você tem a oportunidade de aplicá-las durante a leitura. Então, sem mais delongas, vamos começar.
O código gerado pelos exercícios existentes neste artigo pode ser encontrado aqui.
Pré-requisitos
Se você quer seguir a parte prática desse artigo, alguns pré-requisitos são necessários. Você pode, se não quiser sujar suas mãos, ignorá-los.
Uma conta na AWS:
Se você não tem uma conta na AWS, pode criá-la gratuitamente aqui.
IAM User:
Crie um usuário IAM na sua conta na AWS com permissões administrativas e com chaves de acesso geradas.
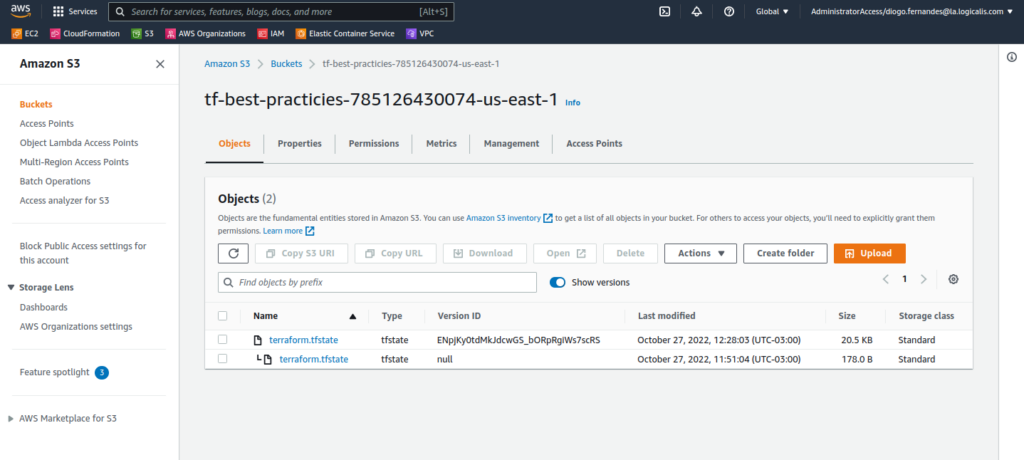
Bucket S3:
Crie o bucket S3 onde vamos armazenar nossos arquivos de estado (tfstate) do Terraform. Um bom nome para ele seria tf-best-practicies-ACCOUNT-ID-us-east-1. Substitua o ACCOUNT-ID pelo número da sua conta AWS.
Tabela DynamoDB:
Para gerenciar o locking do arquivo de estado do Terraform, crie uma tabela no DynamoDB com a hash_key = “LockID” e um atributo { name = “LockID”, type = “S” }. Veja aqui maiores detalhes sobre essa operação.
Para a criação dos componentes do backend remoto em AWS, podemos utilizar os passos especificados neste artigo.
Uma conta no Github, com Personal Access Token:
Vamos armazenar nosso código em um repositório no Github e utilizaremos SSH para enviar nossos arquivos para o repositório remoto.
Terraform:
Você pode instalá-lo para o seu sistema operacional predileto por aqui.
Terraform Docs:
Você pode instalá-lo para o seu sistema operacional predileto por aqui.
Prática 1 – Armazene seu código Terraform em um repositório Git
A IaC se beneficia do GitHub como ferramenta de colaboração e source of truth. O GitHub é uma plataforma de DevOps e colaboração que é conhecida por seus recursos de controle de versão. Sistemas de controle de versão (VCS) são comumente usados para manter uma coleção de arquivos de software, permitindo que os usuários documentem, rastreiem, desfaçam e mesclem alterações feitas por vários usuários em tempo real.
O GitHub também serve como uma plataforma de colaboração para milhões de desenvolvedores por meio de conversas em pull requests e problemas. Ao usar o GitHub para controle de versão e colaboração, os operadores podem cooperar melhor com os desenvolvedores de aplicativos durante todo o ciclo de vida do software. Como usuário do Terraform, você deve salvar seus arquivos de configuração em um VCS.
Dica de sucesso 1:
Sempre mantenha seu código versionado e armazenado em um repositório remoto.
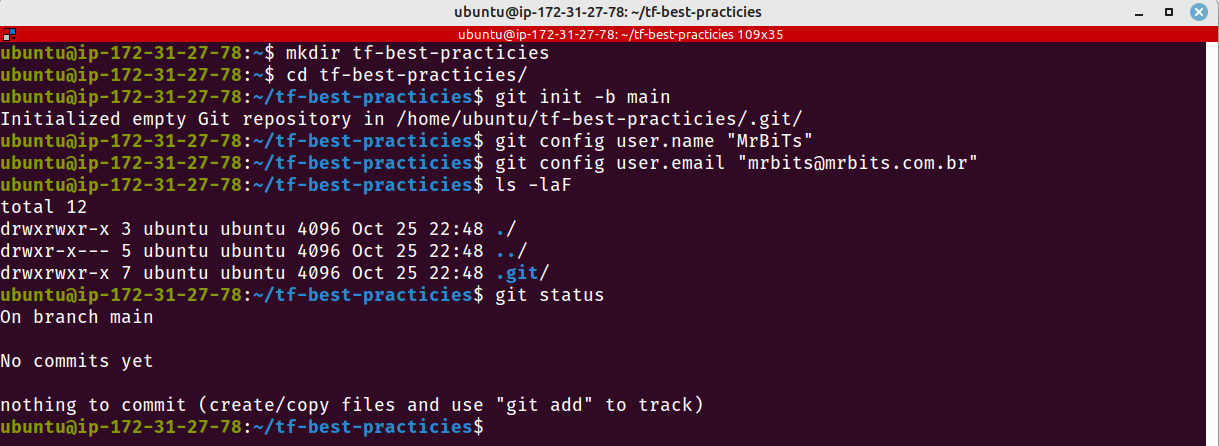
Criar um repositório Git para armazenar seu código é a primeira melhor prática que eu recomendo quando você está iniciando um projeto Terraform. Vamos criar nosso repositório Git antes de começar a codificar nossa infraestrutura.
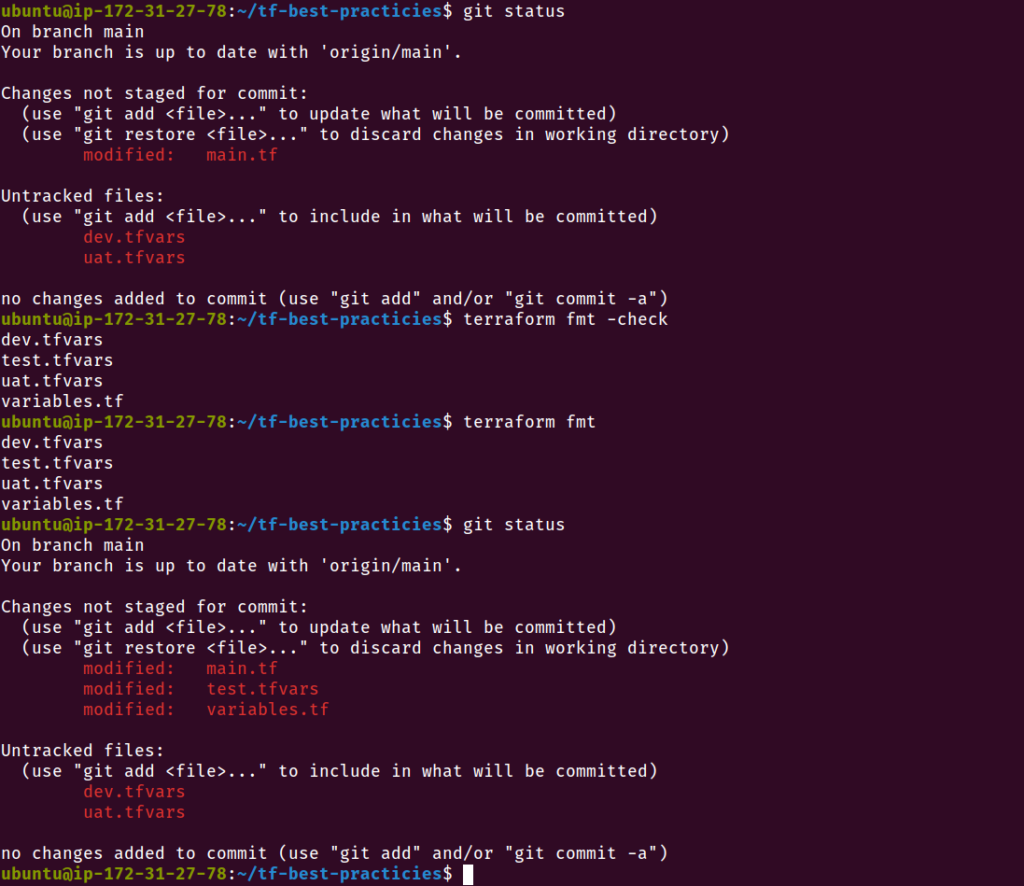
Vamos inicializar um repositório Git local e criar um repositório remoto no Github.
mkdir tf-best-practicies
cd tf-best-practicies
git init -b main
git config user.name "<Name to use in Git commits>"
git config user.emaikl "<Email to use in Git commits>"
ls -laF
git status
Fig. 1 – Inicialização do repositório Git local
Crie um repositório no Github chamado tf-best-practicies.
Prática 2 – Use .gitignore
Usamos o arquivo .gitignore para dizer ao Git que desejamos excluir de nossos commits arquivos de estado do Terraform, arquivos de backup, planos de execução, entre outros.
O comando terraform init cria um diretório de trabalho que contém os arquivos de configuração do Terraform. Este comando prepara o diretório de trabalho para uso do Terraform. Também descobrirá, baixará e instalará automaticamente os plug-ins de provedor apropriados publicados no Terraform Registry público ou em um registro de provedor de terceiros.
Todos os arquivos baixados localmente não precisam ser enviados para o repositório Git com outros arquivos de configuração do Terraform. Além disso, outros arquivos como chaves ssh, arquivos de estado e arquivos de log ou planos de execução também não precisam ser enviados.
Você pode informar ao Git quais arquivos e diretórios devem ser ignorados ao fazer o commit, colocando um arquivo .gitignore no diretório raiz do seu projeto. Configure o arquivo .gitignore em seu repositório para compartilhar as regras de ignorar com outros usuários que possam querer cloná-lo. Um arquivo .gitignore local normalmente deve ser mantido no diretório raiz do projeto.
Abaixo você encontrará o .gitignore que eu uso em todos os meus projetos mas você pode modificá-lo de acordo com as suas necessidades. Todos os arquivos configurados no .gitignore a seguir serão ignorados pelo Git e, portanto, não serão versionados pelo Git e nem enviados para o repositório remoto.
Dica de sucesso 2:
Sempre tenha um arquivo .gitignore em seu repositório com as regras para evitar que arquivos desnecessários sejam gerenciados pelo versionador.
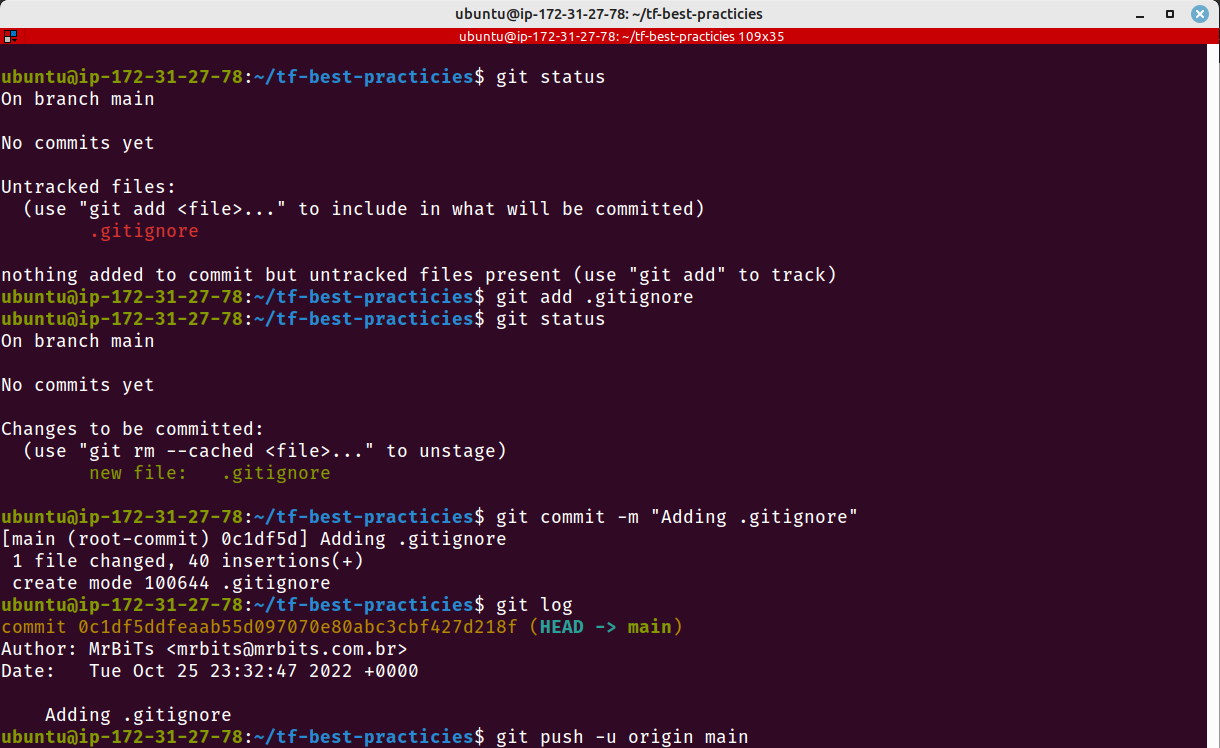
Vamos criar um arquivo .gitignore e enviá-lo ao repositório remoto. Execute em seu computador, no diretório tf-best-practicies, os comandos abaixo:
cat <<__EOF__>.gitignore
# Local .terraform directories
**/.terraform/*
# .tfstate files
*.tfstate
*.tfstate.*
# Crash log files
crash.log
# Exclude all .tfvars files, which are likely to contain sentitive data, such as
# password, private keys, and other secrets. These should not be part of version
# control as they are data points which are potentially sensitive and subject
# to change depending on the environment.
#
terraform/**/*.tfvars
# Ignore override files as they are usually used to override resources locally and so
# are not checked in
override.tf
override.tf.json
*_override.tf
*_override.tf.json
# Include tfplan files to ignore the plan output of command: terraform plan -out=tfplan
*tfplan*
# Ignore CLI configuration files
.terraformrc
terraform.rc
.terraform.*
# Ignore autoenv configuration
.env
# Ignore SSH keys
*id_rsa*
# Ignore zip files
*.zip
__EOF__
git status
git add .gitignore
git status
git commit -m "Adding .gitignore"
git log
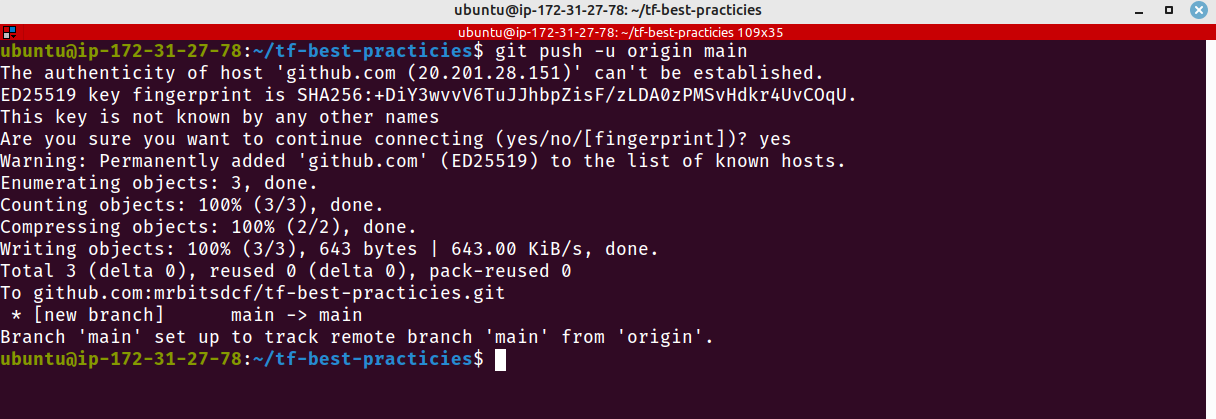
git remote add origin URL_DO_SEU_REPOSITORIO
git push -u origin main
Fig. 2 – Enviando .gitignore para o GithubFig. 3 – Enviando .gitignore para o GithubFig. 4 – Nosso repositório com o .gitignore
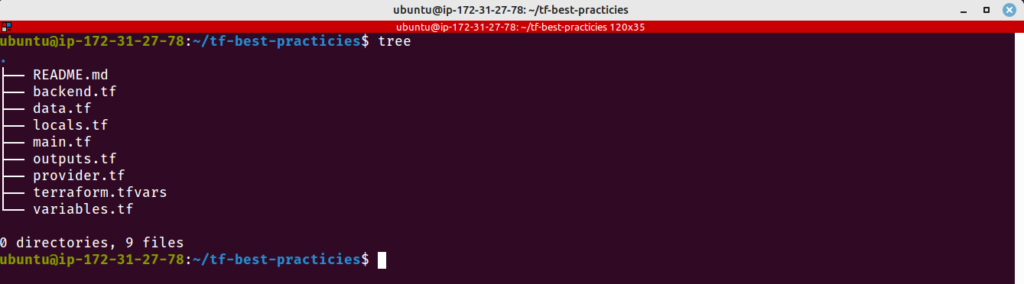
Prática 3 – Use uma estrutura de arquivos consistente
Não há uma estrutura rígida de arquivos e diretórios exigida pelo Terraform. Para um projeto pequeno, pode ser suficiente apenas um arquivo contendo as variáveis, os outputs e os resources, mas recomendo que os projetos sejam formatados da mesma maneira, independente de seu tamanho.
Posso dar algumas sugestões para projetos simples:
Use o diretório modules na estrutura do seu projeto quando há módulos. Módulos são diretórios que contém arquivos de configuração do Terraform que foram criados de maneira a permitir reutilização;
Um arquivo README.md deve ser incluído pelo menos na raíz do projeto, mas podemos manter um para cada módulo, com a documentação de uso do módulo específico;
Crie main.tf para chamar os módulos, locals.tf para armazenar configurações locais e data.tf para os recursos data;
Use um arquivo provider.tf com os detalhes do provider;
Use um arquivo backend.tf com os detalhes de backend do projeto;
Use um arquivo variables.tf com as configurações das variáveis utilizadas;
Use um arquivo outputs.tf com os outputs do projeto;
Use um arquivo terraform.tfvars para carregar automaticamente as variáveis.
Dica de sucesso 3:
Use sempre estruturas consistentes de diretórios e arquivos, não importa o tamanho de seu projeto.
Vamos criar uma estrutura de arquivos consistente, a título de exemplo. Você pode adicionar mais arquivos se quiser, mas lembre-se: a estrutura de arquivos devem ser consistente entre seus projetos. Para isso, execute os comandos abaixo:
Fig. 6 – Enviando modificações para o repositório remoto
Prática 4 – Auto-formatação de arquivos Terraform
Legibilidade conta. Devemos sempre pensar que construímos código que será lido por outras pessoas em algum momento. Terraform, seja em JSON ou em HCL, segue os mesmos guias de estilo de outras linguagens de programação. Uma chave não fechada ou uma identação mal feita pode tornar seu código difícil de ler e difícil de manter.
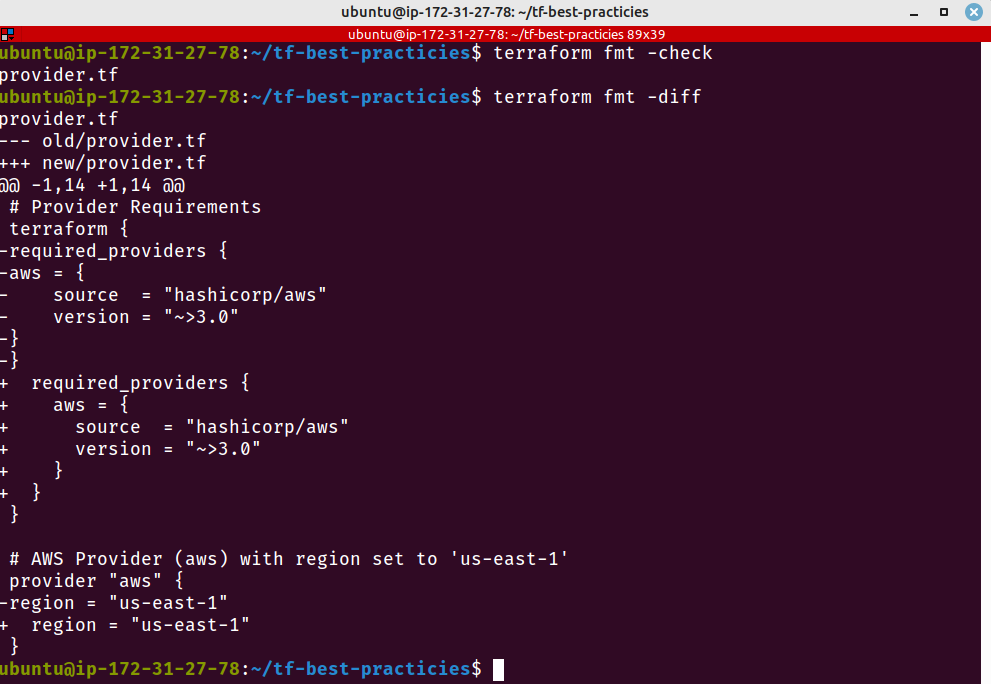
Pensando nessa questão, a Hashicorp inseriu no Terraform um comando fmt, que corrige as discrepâncias do código. Os arquivos do Terraform são reescritos em uma estrutura e estilo consistentes utilizando o comando terraform fmt.
Dica de sucesso 4:
Sempre use terraform fmt -diff para verificar e formatar seus arquivos Terraform antes de enviá-los ao repositório remoto.
Vamos criar um arquivo provider.tf, sem nenhuma formatação.
cat <<__EOF__>provider.tf
# Provider Requirements
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~>3.0"
}
}
}
# AWS Provider (aws) with region set to 'us-east-1'
provider "aws" {
region = "us-east-1"
}
__EOF__
Com o arquivo preparado, mas sem formatação, vamos rodar os seguintes comandos:
terraform fmt -check
terraform fmt -diff
Fig. 7 – terraform fmt corrigindo formatação do arquivo provider.tf
Não nos esqueçamos nunca de enviar as modificações ao repositório Git remoto. Já vamos também inicializar nosso projeto.
git status
git add provider.tf
git commmit -m 'Add provider.tf, format Terraform files'
git push
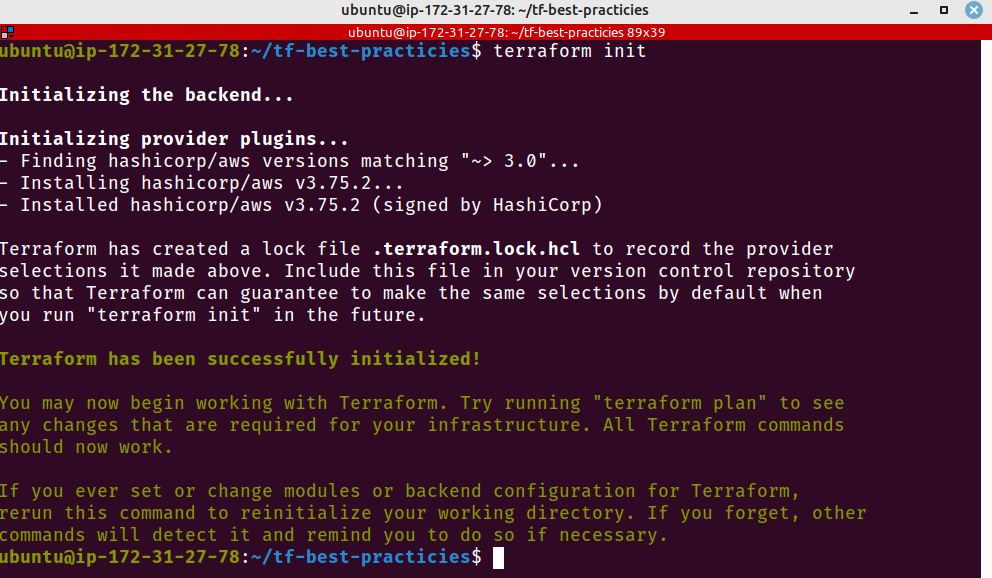
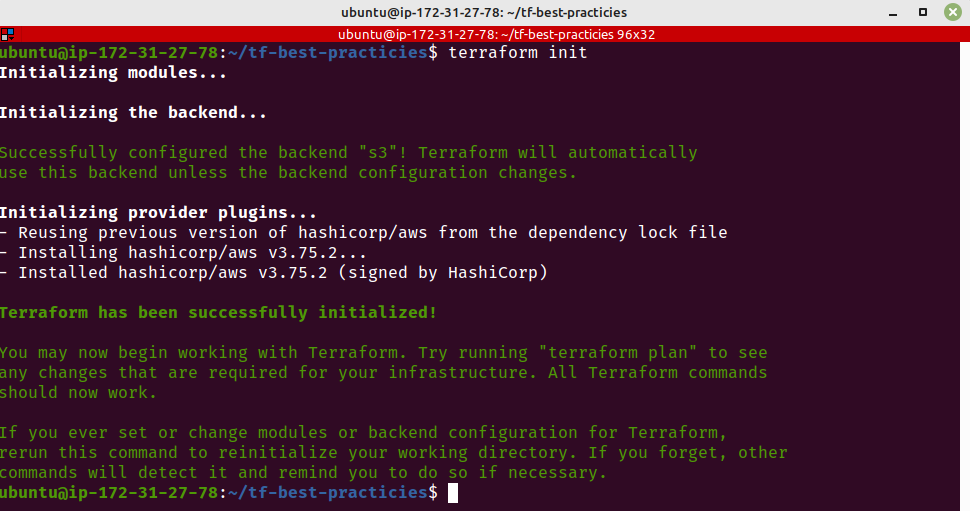
terraform init
Fig. 8 – terraform init
Prática 5 – Evite valores Hard Coded
Algumas vezes provavelmente acabamos codificando valores padrão para as configurações. Quem nunca pensou algo como : “Vou fazer isso funcionar por enquanto e descobrir como melhorá-lo mais tarde, quando tiver algum tempo livre”. Mas você recebeu uma nova tarefa e esqueceu o que fez para “fazer funcionar agora”. Você também se preocupa em arruinar algo que funciona tentando melhorá-lo.
Isso fere nossas boas práticas e nos impede de criar um bom código, reaproveitável e modular. Então, é uma prática recomendada evitar recursos de hard coding nos arquivos de configuração do Terraform. Em vez disso, os valores devem ser colocados como variáveis.
Dica de sucesso 5:
Sempre defina variáveis, atribua valores a elas e as use onde necessitar.
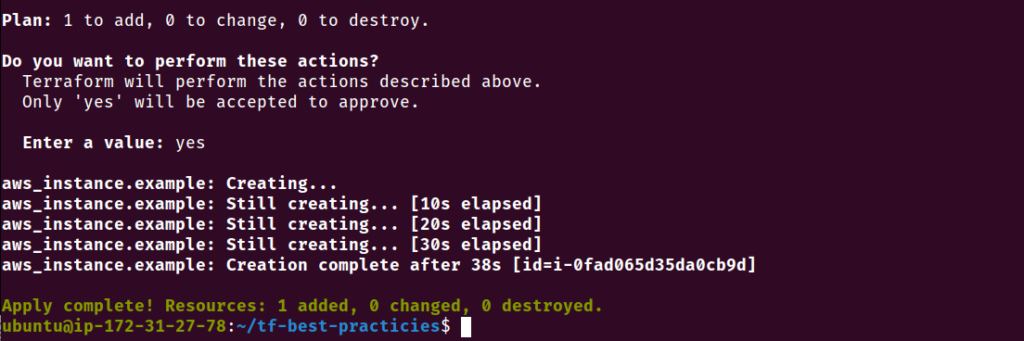
No exemplo abaixo temos a definição de uma instância EC2 com AMI, tipo e nome hard coded. Esse código não é reaproveitável.
resource "aws_instance" "example" {
ami = "ami-005de95e8ff495156"
instance_type = "t2.micro"
tags = {
Name = "instance-1"
}
}
Ao invés disso, declare variáveis e use-as na definição do resource. Execute os comandos abaixo para criar um arquivo variables.tf, contendo as definições das variáveis, e use-as no main.tf para criar nossa instância EC2.
cat <<__EOF__>variables.tf
variable "instance_ami" {
description = "Value of the AMI ID for the EC2 instance"
type = string
default = "ami-005de95e8ff495156"
}
variable "instance_type" {
description = "Value of the Instance Type for the EC2 instance"
type = string
default = "t2.micro"
}
variable "instance_name" {
description = "Value of the Name Tag for the EC2 instance"
type = string
default = "instance-1"
}
__EOF__
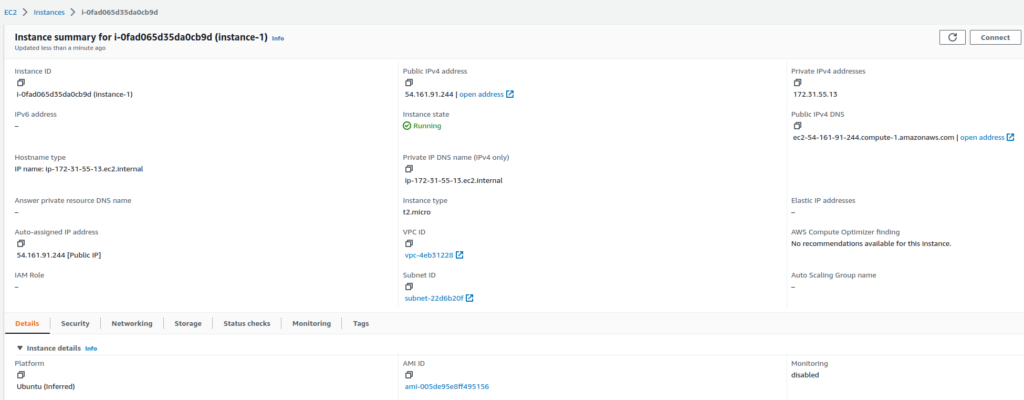
Fig. 9 – Final da execução do terraform applyFig. 10 – Instância EC2 criada pelo Terraform
Não se esqueça de enviar as modificações no código para o Github.
Prática 6 – Siga sempre uma convenção de nomenclatura
Terraform é bastante subjetivo quando se trata do nome de um recurso. A única regra que, se quebrada, gera erros durante a execução do código é a de que não pode haver dois recursos diferentes com o mesmo nome.
Não há rigidez na criação de um nome de recurso, mas podemos definir algumas padronizações de forma a ter legibilidade e evitar confusão. Isso pode ser acordado com seu time ou definido em documentos de padronização da sua companhia.
Ao invés de – (hífen), use _ (underscore) em todos os lugares (nomes de recursos, variáveis, outputs, locals, etc);
Use somente letras minúsculas e números;
Use nomes no singular;
Use – (hífen) nos argumentos e valores de variáveis, principalmente os que são visíveis pelos usuários;
Use nomes descritivos para cada recuros. Um Security Group chamado 133_zebra é menos descritivo que um Security Group chamado secgroup_alb_wordpress.
Dica de sucesso 6:
Defina normas e padrões de nomenclatura com seu time e siga-os o tempo todo.
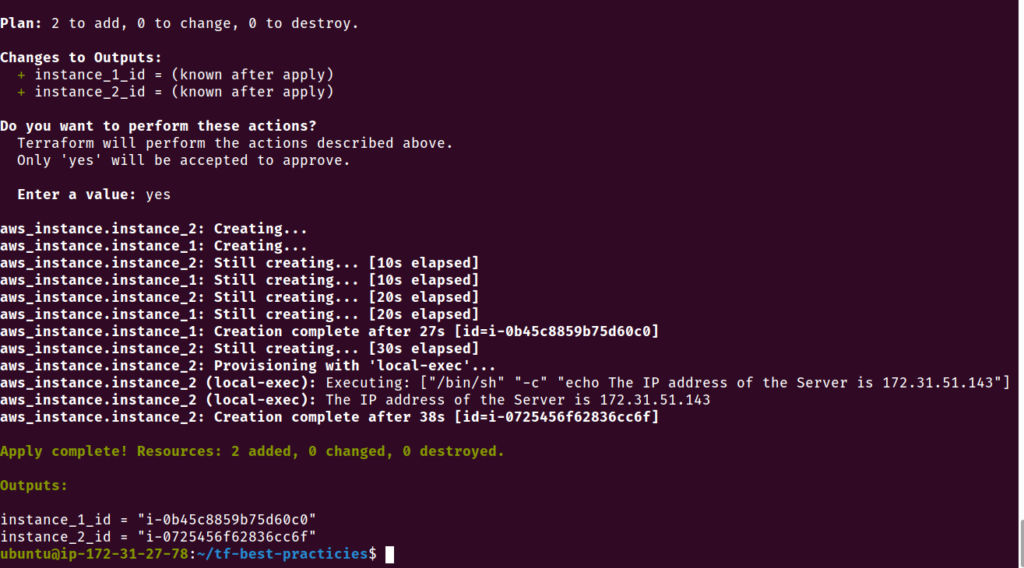
No exemplo seguinte, vamos ver os nomes de nossos recursos e variáveis definidos em letras minúsculas, com números e _ (underscores), enquanto os valores das variáveis são definidas com – (hífen). Definimos também o arquivo outputs.tf, seguindo as mesmas normas de nomenclatura.
cat <<__EOF__>variables.tf
variable "instance_1_ami" {
description = "Value of the AMI ID for the EC2 instance"
type = string
default = "ami-005de95e8ff495156"
}
variable "instance_1_type" {
description = "Value of the Instance Type for the EC2 instance"
type = string
default = "t2.micro"
}
variable "instance_1_name" {
description = "Value of the Name Tag for the EC2 instance"
type = string
default = "instance-1"
}
__EOF__
cat <<__EOF__>outputs.tf
output "instance_1_id" {
description = "The ID of the instance-1"
value = try(aws_instance.instance_1.id)
}
__EOF__
Executamos nosso novo código:
terraform plan
terraform apply
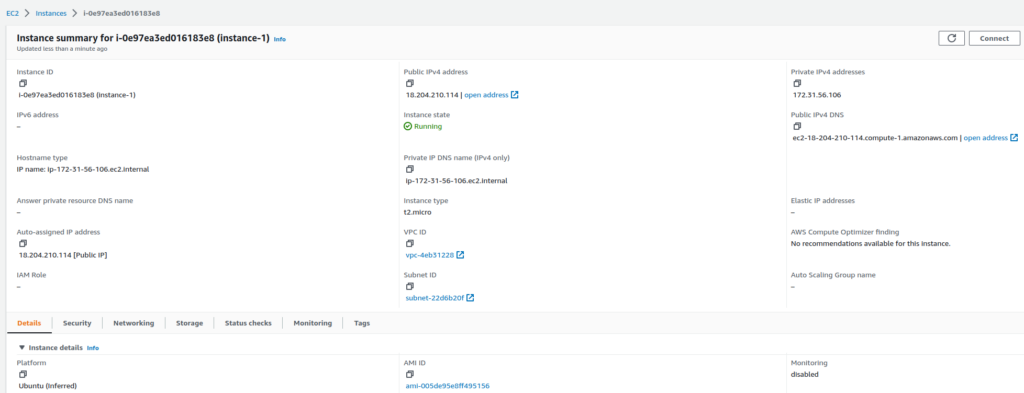
Uma nova instância EC2 foi criada, substituindo a instância que foi criada na prática 5.
Fig. 11 – Nova instância EC2 criada
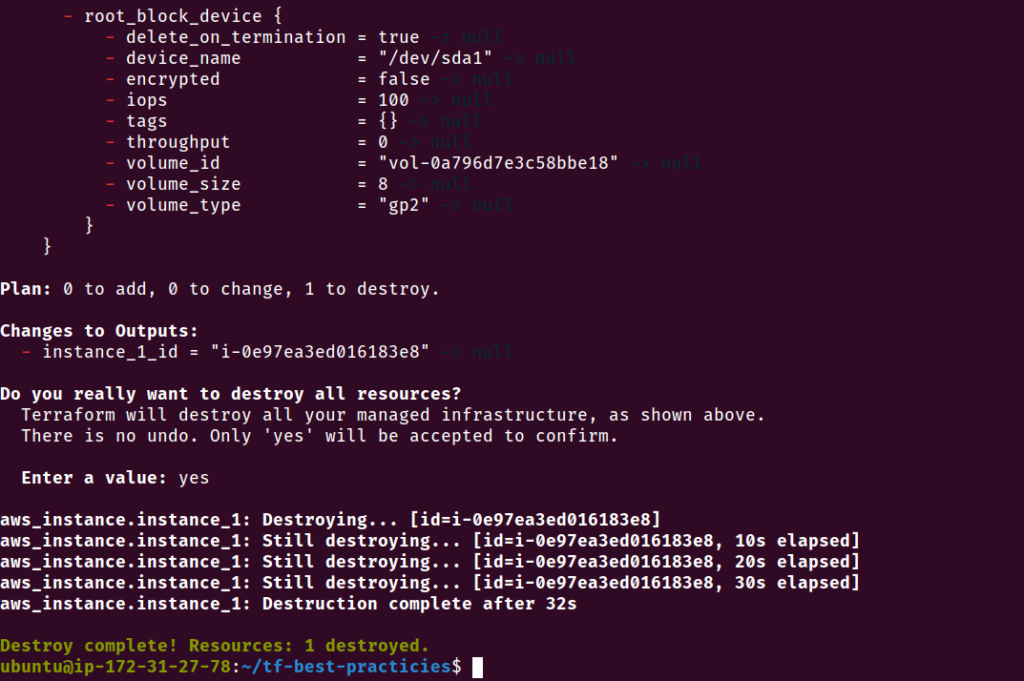
Antes da próxima prática, vamos remover os recursos que criamos na AWS até agora.
terraform destroy
Fig. 12 – Recursos removidos
Não se esqueça de enviar suas modificações para o Github.
Prática 7 – Use a variável self
As variáveis gerais são úteis de várias maneiras, mas falta um elemento importante: a capacidade de prever o futuro. Uma variável self é um tipo de valor exclusivo para seus recursos e preenchido no momento da criação. Esse tipo de variável é utilizado quando o valor de uma variável é desconhecido antes da implantação da infraestrutura. É importante observar que apenas os blocos connection e provisioner do Terraform habilitam essas variáveis.
Por exemplo, self.private_ip pode ser usado para obter o endereço IP privado de uma máquina após a implantação inicial, mesmo que o endereço IP não seja conhecido até que seja atribuído.
Dica de sucesso 7:
Use a variável self quando você precisa conhecer o valor de uma variável antes do deploy da infraestrutura.
cat <<__EOF__>main.tf
resource "aws_instance" "instance_1" {
ami = var.instance_1_ami
instance_type = var.instance_1_type
tags = {
Name = var.instance_1_name
}
}
resource "aws_instance" "instance_2" {
ami = var.instance_2_ami
instance_type = var.instance_2_type
tags = {
Name = var.instance_2_name
}
provisioner "local-exec" {
command = "echo The IP address of the Server is \${self.private_ip}"
on_failure = continue
}
}
__EOF__
cat <<__EOF__>variables.tf
variable "instance_1_ami" {
description = "Value of the AMI ID for the EC2 instance"
type = string
default = "ami-005de95e8ff495156"
}
variable "instance_1_type" {
description = "Value of the Instance Type for the EC2 instance"
type = string
default = "t2.micro"
}
variable "instance_1_name" {
description = "Value of the Name Tag for the EC2 instance"
type = string
default = "instance-1"
}
variable "instance_2_ami" {
description = "Value of the AMI ID for the EC2 instance"
type = string
default = "ami-005de95e8ff495156"
}
variable "instance_2_type" {
description = "Value of the Instance Type for the EC2 instance"
type = string
default = "t2.micro"
}
variable "instance_2_name" {
description = "Value of the Name Tag for the EC2 instance"
type = string
default = "instance-2"
}
__EOF__
cat <<__EOF__>outputs.tf
output "instance_1_id" {
description = "The ID of the instance-1"
value = try(aws_instance.instance_1.id)
}
output "instance_2_id" {
description = "The ID of the instance-2"
value = try(aws_instance.instance_2.id)
}
__EOF__
Vamos executar nosso código.
terraform plan
terraform apply
Fig. 13 – Variável self mostrando seu valor em tempo de deploy
Não se esqueça de mandar seu código para o Github e destruir os recursos lançados (usando terraform destroy)
Prática 8 – Use módulos
Terraform nos permite projetar configurações cada vez mais sofisticadas para gerenciar nossa infraestrutura. Entretanto, nosso arquivo ou diretório de configuração não tem limites e pode ser prejudicial para a legibilidade, manutenção e replicação do código. Isso pode ser mitigado usando módulos.
Um módulo é um contêiner para uma coleção de recursos relacionados. Os módulos podem ser usados para construir abstrações leves, permitindo que sua infraestrutura seja descrita em termos de arquitetura e não em termos de objetos físicos. Você pode colocar seu código em um módulo Terraform e reutilizá-lo várias vezes ao longo da vida útil do seu projeto Terraform.
Por exemplo, você poderá reutilizar o código do mesmo módulo nos ambientes Dev e QA, em vez de copiar e colar o mesmo código.
Todo profissional do Terraform deve empregar módulos de acordo com as seguintes diretrizes:
Comece a escrever sua configuração;
Organize e encapsule seu código usando módulos locais;
Compartilhe módulos com sua equipe após a publicação.
Dica de sucesso 8:
Sempre use módulos. Você vai economizar muito tempo de codificação. Não há necessidade de reinventar a roda.
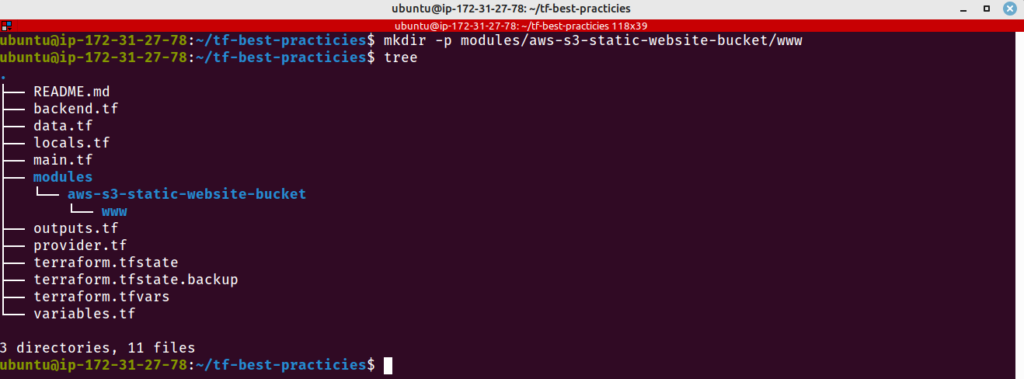
Módulos nos auxiliam a reutilizar código, diminuindo o tempo de desenvolvimento do nosso projeto. Vamos seguir o passo-a-passo para programar e usar um módulo que irá criar dois buckets S3.
mkdir -p modules/aws-s3-static-website-bucket/www
tree
Fig. 14 – Estrutura de projeto Terraform com módulos
Execute os comandos abaixo para criar os arquivos necessários para o funcionamento do módulo.
cat <<__EOF__>modules/aws-s3-static-website-bucket/README.md
AWS S3 Static Website Bucket Module
===================================
Modulo para criar buckets S3 para Websites
------------------------------------------
__EOF__
cat <<__EOF__>modules/aws-s3-static-website-bucket/variables.tf
variable "bucket_prefix" {
description = "Prefix of the s3 bucket. We need to guarantee that bucket name is unique."
type = string
}
variable "tags" {
description = "Tags to set on the bucket."
type = map(string)
default = {}
}
__EOF__
cat <<__EOF__>modules/aws-s3-static-website-bucket/outputs.tf
output "arn" {
description = "ARN of the bucket"
value = aws_s3_bucket.s3_bucket.arn
}
output "name" {
description = "Name (id) of the bucket"
value = aws_s3_bucket.s3_bucket.id
}
output "domain" {
description = "Domain name of the bucket"
value = aws_s3_bucket_website_configuration.s3_bucket.website_domain
}
__EOF__
O comando abaixo vai criar os arquivos main.tf e outputs.tf na raiz do nosso projeto Terraform.
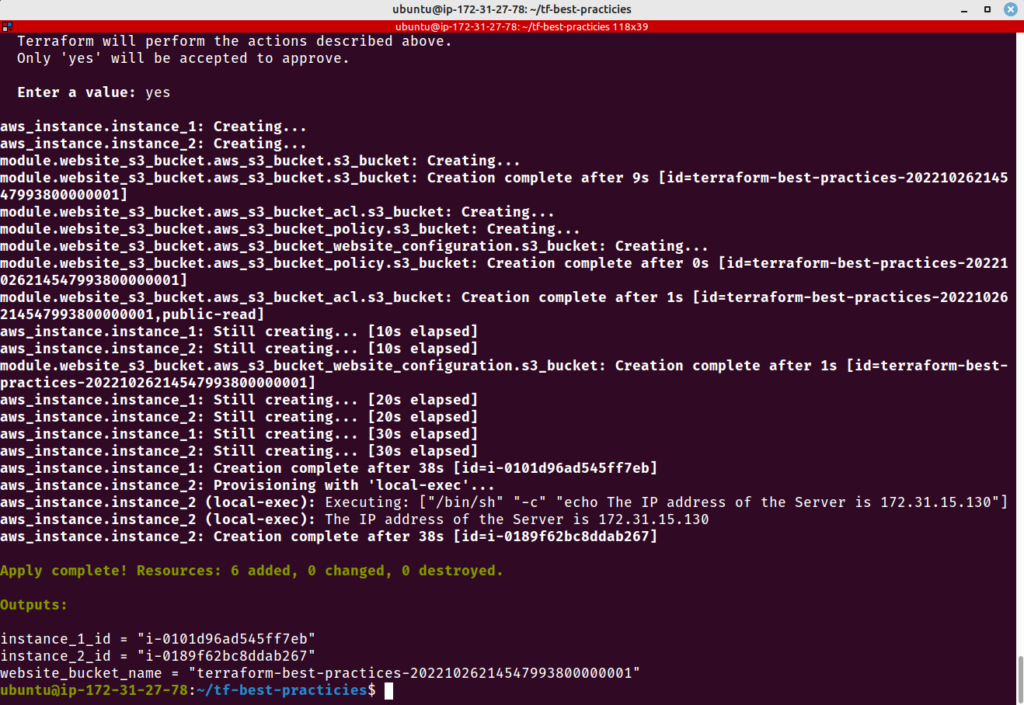
cat <<__EOF__>main.tf
resource "aws_instance" "instance_1" {
ami = var.instance_1_ami
instance_type = var.instance_1_type
tags = {
Name = var.instance_1_name
}
}
resource "aws_instance" "instance_2" {
ami = var.instance_2_ami
instance_type = var.instance_2_type
tags = {
Name = var.instance_2_name
}
provisioner "local-exec" {
command = "echo The IP address of the Server is \${self.private_ip}"
on_failure = continue
}
}
module "website_s3_bucket" {
source = "./modules/aws-s3-static-website-bucket"
bucket_prefix = "terraform-best-practices-"
tags = {
Terraform = "true"
Environment = "test"
}
}
__EOF__
cat <<__EOF__>outputs.tf
output "instance_1_id" {
description = "The ID of the instance-1"
value = try(aws_instance.instance_1.id)
}
output "instance_2_id" {
description = "The ID of the instance-2"
value = try(aws_instance.instance_2.id)
}
output "website_bucket_arn" {
description = "ARN of the bucket"
value = module.website_s3_bucket.arn
}
output "website_bucket_name" {
description = "Name (id) of the bucket"
value = module.website_s3_bucket.name
}
output "website_bucket_domain" {
description = "Domain name of the bucket"
value = module.website_s3_bucket.domain
}
__EOF__
Adicionalmente, criaremos dois arquivos HTML para compor nosso site estático armazenado no S3.
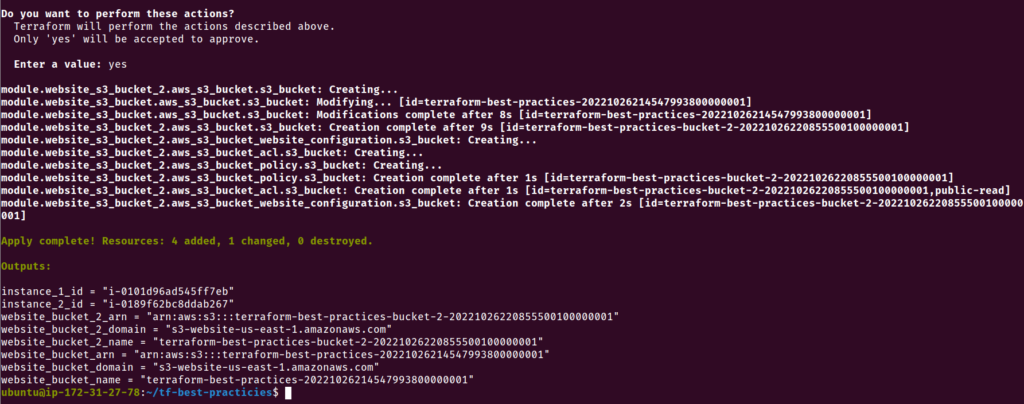
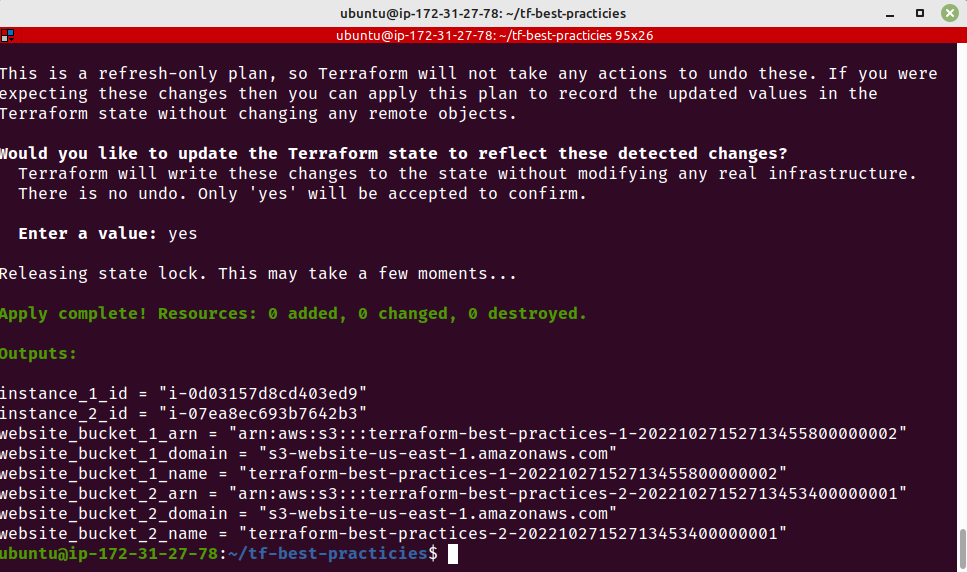
Agora vamos criar um novo bucket S3, reaproveitando o módulo já desenvolvido. Execute os comandos abaixo:
cat <<__EOF__>>outputs.tf
output "website_bucket_2_arn" {
description = "ARN of the bucket"
value = module.website_s3_bucket_2.arn
}
output "website_bucket_2_name" {
description = "Name (id) of the bucket"
value = module.website_s3_bucket_2.name
}
output "website_bucket_2_domain" {
description = "Domain name of the bucket"
value = module.website_s3_bucket_2.domain
}
__EOF__
Não vamos nos esquecer de enviar o código modificado para nosso Github. Em seguida, antes de passarmos para a próxima prática, vamos eliminar os recursos criados.
O parâmetro -var-file é usado para para informar ao Terraform um arquivo de parâmetros que devem ser utilizados como valores das variáveis esperadas pelo código.
Isso permite que você salve os valores das variáveis de entrada em um arquivo com o sufixo .tfvars, que pode ser armazenado no versionador para qualquer ambiente de variável que você precise implantar.
Se o diretório atual contiver um arquivo terraform.tfvars, o Terraform o usará automaticamente para preencher as variáveis. Se o arquivo tiver um nome diferente, você poderá fornecê-lo explicitamente usando o sinalizador -var-file.
Uma vez que você tenha um ou mais arquivos .tfvars, você pode usar o sinalizador -var-file para direcionar o Terraform sobre qual arquivo ele deve usar para fornecer variáveis de entrada para o comando Terraform.
Esta é mais uma ferramenta que nos possibilita reaproveitar o código Terraform desenvolvido para criar ambientes diferentes como, por exemplo, ambientes de desenvolvimento, testes e produção.
Dica de sucesso 9:
Matenha múltiplos arquivos .tfvars com definição de variáveis, que podem ser informados aos comandos terraform plan ou terraform apply através do argumento -var-file.
Vamos para os nossos testes. Execute os comandos abaixo:
cat <<__EOF__>main.tf
resource "aws_instance" "instance_1" {
ami = var.instance_1_ami
instance_type = var.instance_1_type
tags = {
Name = var.instance_1_name
}
}
resource "aws_instance" "instance_2" {
ami = var.instance_2_ami
instance_type = var.instance_2_type
tags = {
Name = var.instance_2_name
}
provisioner "local-exec" {
command = "echo The IP address of the Server is \${self.private_ip}"
on_failure = continue
}
}
module "website_s3_bucket_1" {
source = "./modules/aws-s3-static-website-bucket"
bucket_prefix = var.website_s3_bucket_1_prefix
tags = {
Terraform = var.terraform
Environment = var.environment
}
}
module "website_s3_bucket_2" {
source = "./modules/aws-s3-static-website-bucket"
bucket_prefix = var.website_s3_bucket_2_prefix
tags = {
Terraform = var.terraform
Environment = var.environment
}
}
__EOF__
cat <<__EOF__>variables.tf
variable "instance_1_ami" {
description = "Value of the AMI ID for the EC2 instance"
type = string
}
variable "instance_1_type" {
description = "Value of the Instance Type for the EC2 instance"
type = string
}
variable "instance_1_name" {
description = "Value of the Name Tag for the EC2 instance"
type = string
}
variable "instance_2_ami" {
description = "Value of the AMI ID for the EC2 instance"
type = string
}
variable "instance_2_type" {
description = "Value of the Instance Type for the EC2 instance"
type = string
}
variable "instance_2_name" {
description = "Value of the Name Tag for the EC2 instance"
type = string
}
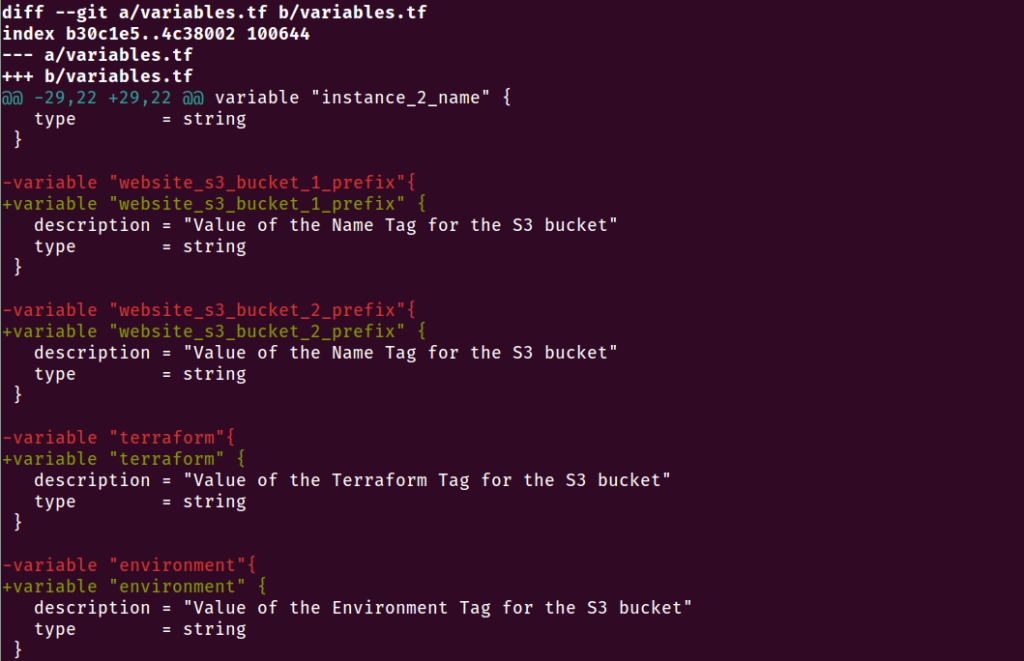
variable "website_s3_bucket_1_prefix"{
description = "Value of the Name Tag for the S3 bucket"
type = string
}
variable "website_s3_bucket_2_prefix"{
description = "Value of the Name Tag for the S3 bucket"
type = string
}
variable "terraform"{
description = "Value of the Terraform Tag for the S3 bucket"
type = string
}
variable "environment"{
description = "Value of the Environment Tag for the S3 bucket"
type = string
}
__EOF__
cat <<__EOF__>outputs.tf
output "instance_1_id" {
description = "The ID of the instance-1"
value = try(aws_instance.instance_1.id)
}
output "instance_2_id" {
description = "The ID of the instance-2"
value = try(aws_instance.instance_2.id)
}
output "website_bucket_1_arn" {
description = "ARN of the bucket"
value = module.website_s3_bucket_1.arn
}
output "website_bucket_1_name" {
description = "Name (id) of the bucket"
value = module.website_s3_bucket_1.name
}
output "website_bucket_1_domain" {
description = "Domain name of the bucket"
value = module.website_s3_bucket_1.domain
}
output "website_bucket_2_arn" {
description = "ARN of the bucket"
value = module.website_s3_bucket_2.arn
}
output "website_bucket_2_name" {
description = "Name (id) of the bucket"
value = module.website_s3_bucket_2.name
}
output "website_bucket_2_domain" {
description = "Domain name of the bucket"
value = module.website_s3_bucket_2.domain
}
__EOF__
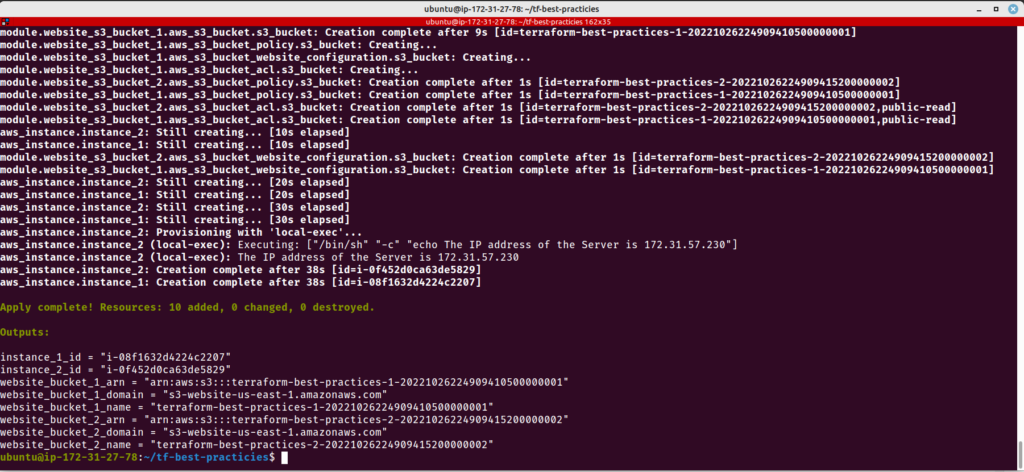
Vamos executar nosso código Terraform informando o arquivo .tfvars que criamos:
terraform init
terraform plan -var-file=test.tfvars
terraform apply -var-file=test.tfvars
Fig. 17 – Criação de recursos utilizando -var-file
Não se esqueça de enviar o código para o Github e excluir os recursos criados. Também para o comando terraform destroy teremos que utilizar o argumento -var-file.
terraform destroy -var-file=test.tfvars
Prática 10 – Armazene o arquivo de estado do Terraform em um storage remoto
O arquivo de estado (tfstate) do Terraform é um dos componentes mais importantes do projeto. É ele que mantém os dados do que foi aplicado, do que deve ser modificado para manter a integridade da infraestrutura. Perder esse arquivo pode simplesmente invalidar todo o seu código Terraform.
Por padrão, o Terraform salva o estado de uma infraestrutura em um arquivo tfstate armazenado localmente. Embora isso possa ser suficiente enquanto estamos desenvolvendo nosso código ou testando algo, quando pensamos nos ambientes definitivos ou em um trabalho compartilhado ou em um pipeline de IaC, precisamos armazenar o tfstate em um lugar disponível e tolerante a falhas de diversos tipos. Além disso, quando trabalhamos em um time, precisamos garantir que todos estejam acessando a versão mais atual do arquivo de estado e que somente uma pessoa por vez possa modificá-lo. Para isso usamos o conceito de remote state.
Terraform com acesso compartilhado ao arquivo de estado armazenado em um ambiente remoto é o melhor caminho a se seguir para projetos em grupo. Os problemas apresentados anteriormente são endereçados pelo remote state. Basicamente, usar um remote state significa armazenar o arquivo tfstate em um servidor remoto ao invés de em nossa máquina local e garantir que esse local remoto tenha algum controle de locking desse arquivo. Assim, os times podem ter a certeza de usar sempre o tfstate mais atual.
Dica de sucesso 10:
Quando trabalhamos em um projeto junto a várias outras pessoas, devemos sempre usar backends Terraform que salvam o state file em um armazenamento remoto compartilhado.
Para armazenar o arquivo de estado em um backend remoto em um bucket S3, vamos seguir os passos abaixo, criando nosso bucket e configurando um arquivo backend.tf indicando esse bucket. Substitua ACCOUNTID pelo número da sua conta AWS.
Vamos inicializar o Terraform. Certifique-se de ter executado terraform destroy ao final da Prática 9.
rm -rf .terraform
terraform init
Fig. 18 – Inicializando o Terraform com remote backend
Não se esqueça de enviar seu código para o Github.
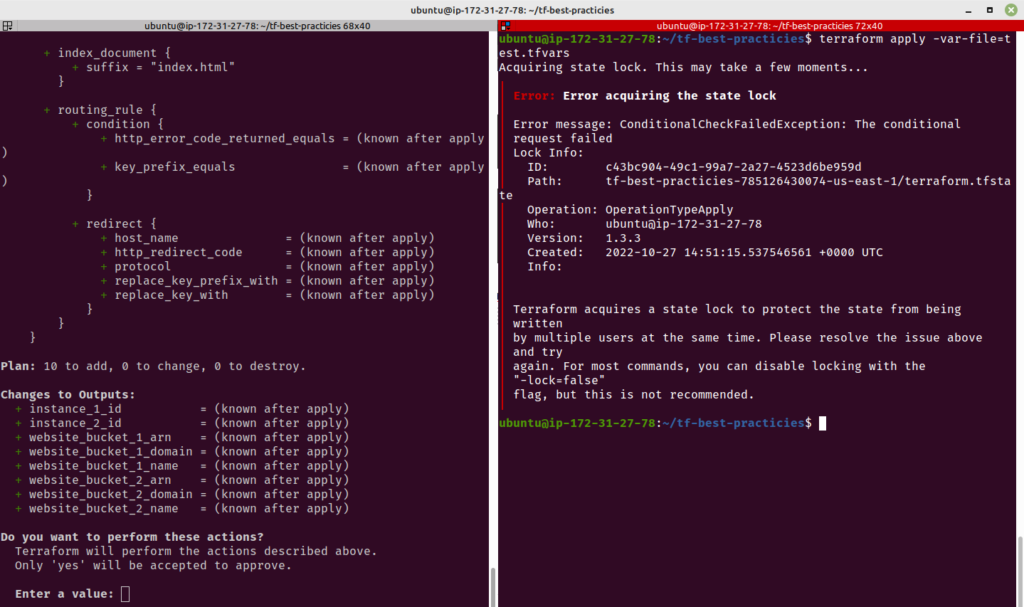
Prática 11 – Bloqueie o arquivo de estado remoto
O estado remoto do Terraform é dividido em duas partes: o arquivo de estado armazenado em um local remoto (discutido na Prática 10) e o state locking.
Quando duas ou mais pessoas estão operando a mesma infraestrutura ao mesmo tempo, podem ocorrer problemas com a criação de recursos se os processos do Terraform tentarem lançar o mesmo recurso.
Nessa situação, se o backend suportar, o Terraform bloqueará o acesso ao arquivo de estato para qualquer operação que possa escrever nele. O bloqueio estado do Terraform é exigido para prevenir outros usuário de simultaneamente destruir ou modificar a infraestrutura.
Há diversos backends remotos possíveis que podemos utilizar no Terraform. Cada um trata o bloqueio do arquivo de estado de uma maneira diferente. Na AWS, esse bloqueio é gerenciado por uma tabela do DynamoDB, cuja criação foi solicitada na sessão de pré-requisitos deste artigo. Se você não a criou, agora é o momento.
Dica de sucesso 11:
Sempre use bloqueio de estado quando seu arquivo de estado estiver armazenado em um backend remoto.
Para entender como o bloqueio de estado funciona, siga os passos abaixo para modificar o arquivo backend.tf, adicionando o parâmetro dynamodb_table. Depois, executaremos dois terraform apply simultâneamente. Não esqueça de enviar suas modificações para o Github.
Caso você não tenha criado a tabela do DynamoDB, execute o comando abaixo. Se a criou, pule para o próximo comando.
Execute o comando terraform apply em duas sessões diferentes, uma após a outra, e veja o comportamento.
Fig.19 – State locking em funcionamento
Prática 12 – Faça cópias de segurança do arquivo de estado
Quando trabalhamos com o Terraform sem informar um backend remoto, notamos dois arquivos criados em nosso diretório de trabalho: terraform.tfstate e terraform.tfstate.backup. Esses arquivos contém o estado da infraestrutura gerenciada pelos arquivos do Terraform que estamos usando. Quando executamos terraform apply, o comando cria um novo terraform.tfstate e move o arquivo corrente para o backup. Em caso de desastre com o arquivo de estado, basta substituí-lo pelo backup.
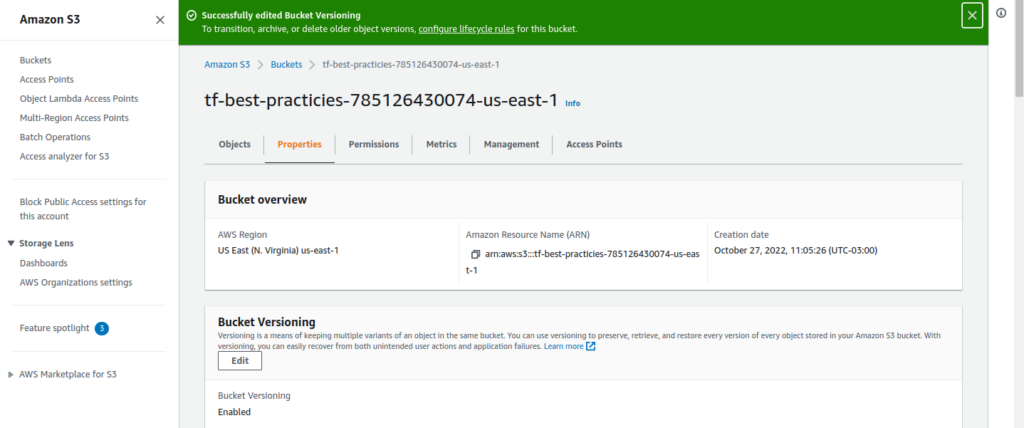
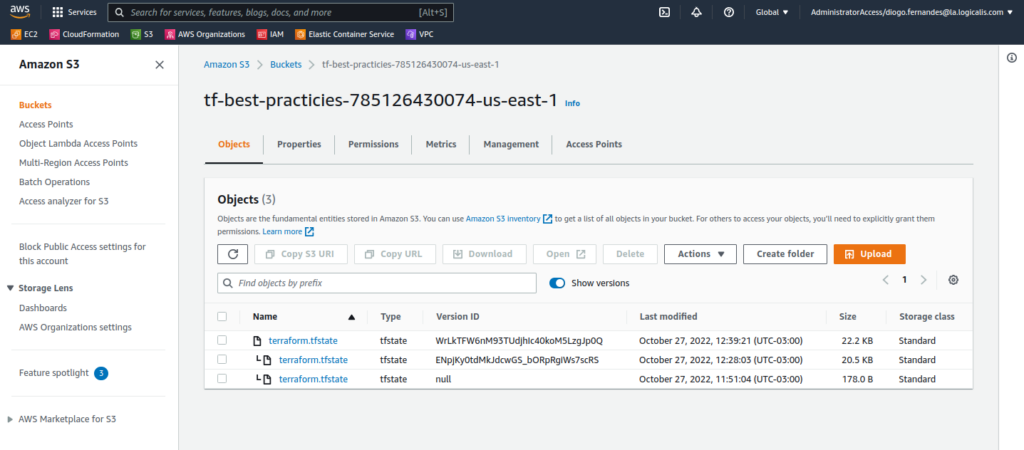
Se estamos usando um backend remoto como o AWS S3, é extremamente recomendado habilitar o versionamento do bucket utilizado. Dessa maneira, se o arquivo de estado é removido ou corrompido, ou mesmo está em um estado incorreto, seremos capazes de recuperá-lo restaurando uma versão prévia do arquivo.
Dica de sucesso 12:
Sempre habilite versionamento ou backup do estado remoto do seu Terraform, para que você possa recuperá-lo em caso de acidente.
Execute os passos abaixo para habilitar o versionamento do bucket S3 utilizado como backend remoto, criar os recursos na AWS e verificar as versões do arquivo de estado.
Fig. 20 – Versionamento de bucket S3 habilitado
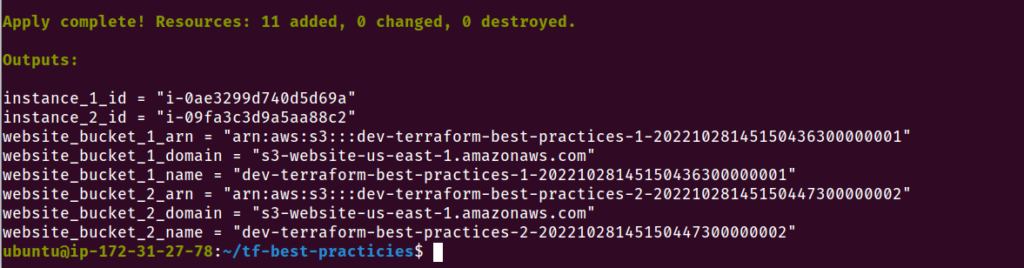
terraform apply -var-file=test.tfvars
Fig. 21 – Arquivo de estado versionado
Prática 13 – Manipule o arquivo de estado somente pelo comando terraform
Graças aos dados de estado, o Terraform lembra qual objeto do mundo real corresponde a cada recurso na configuração, permitindo modificar um objeto existente quando sua declaração de recurso for alterada. O Terraform atualiza automaticamente o estado durante as operações terraform plan, terraform apply e terraform destroy. Dito isso, fazer alterações deliberadas nos dados de estado do Terraform continua sendo necessário em certos casos.
A modificação de dados de estado fora de uma operação normal de terraform pode fazer com que o Terraform perca o controle dos recursos controlados. Recomendamos o uso do comando terraform, uma opção mais segura, que fornece comandos para inspecionar o estado, forçar a recriação, mover recursos e recuperação de desastres.
Para saber mais sobre isso, você pode consultar a documentação oficial aqui.
Dica de sucesso 13:
Sempre manipule o arquivo de estado do Terraform através do comando terraform e evite efetuar mudanças manuais no arquivo.
Fig. 22 – terraform refresh arquivo de estadoFig. 23 – Versões do arquivo de estado após refresh
Prática 14 – Gere um README para cada módulo desenvolvido
O README é, tipicamente, o primeiro arquivo que pessoas que estão começando a trabalhar com algum projeto existente acessa. Do seu advento para cá, as pessoas levaram a sério o pedido do arquivo: LEIA-ME.
Um bom README deve conter informações as mais relevantes e amigáveis informações de um projeto. Em síntese, é um documento que informa os objetivos de um projeto, sua execução, características técnicas, entre outras várias informações. Por ser um arquivo importante, ele deve fazer parte de nossos projetos em Terraform.
Dica de sucesso 14:
Você deve ter um README consistente e informativo em todos os seus módulos e projetos Terraform.
Vamos dar uma olhada em como gerar um README usando um utilitário chamado terraform-docs. Vamos mergulhar nesse utilitário que gera automaticamente um README.md para que você evite ter que escrevê-lo manualmente para variáveis de entrada e saídas. Clique aqui para saber mais sobre ele.
Para gerar um README.md para nosso projeto, siga os passos abaixo (o utilitário terraform-docs deve ter sido previamente instalado).
Vamos enviar os README.md criados para nosso Github.
git status
git add README.md modules/aws-s3-static-website-bucket/README.md
git commit -m "Always have a README"
git push
Vá ao Github e verifique os README.md criados.
Prática 15 – Use e abuse das funções built-in
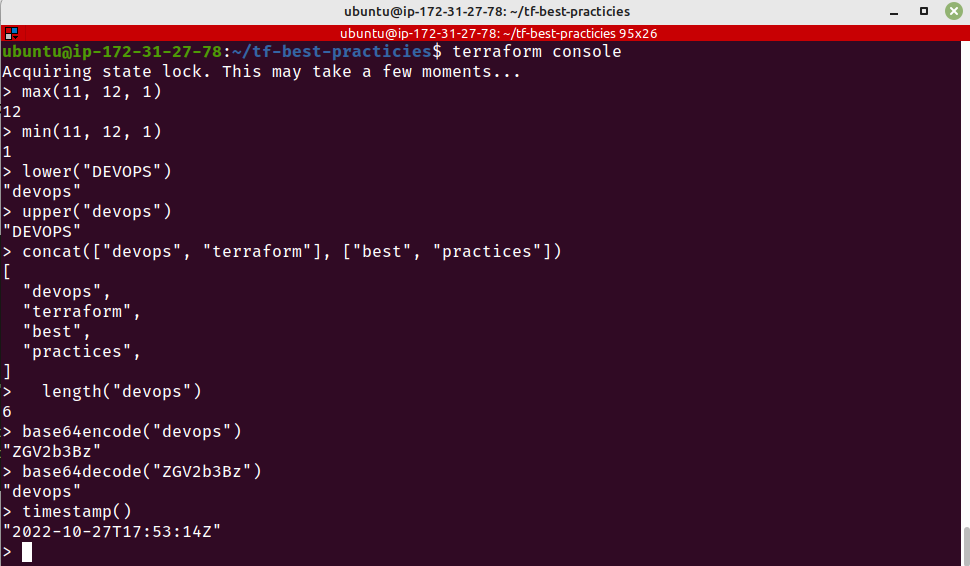
O Terraform tem várias funções incluídas (built-in) que você pode chamar junto a expressões para alterar e combinar variáveis, indo de operações matemáticas atẽ manipulação de arquivos.
Por exemplo, para ler um arquivo de chave privada de SSH, você pode usar uma função do Terraform que permitirá a você estabelecer uma conexão SSH sem ter que armazenar a chave privada no seu código.
Ainda não podemos escrever nossas funções (user-defined functions), mas podemos usar o console do Terraform para testar o comportamento das funções que queremos usar.
Dica de sucesso 15:
Use funções built-in do Terraform para manipular valores em seu código Terraform, executar operações matemáticas, entre outras tarefas.
Vamos executar o console Terraform e testar algumas funções.
Vamos criar uma chave SSH e modificar nossos arquivos Terraform para usar a função file(). Essa função vai ler qualquer chave pública SSH passada para ela e configurará uma instância EC2 com ela.
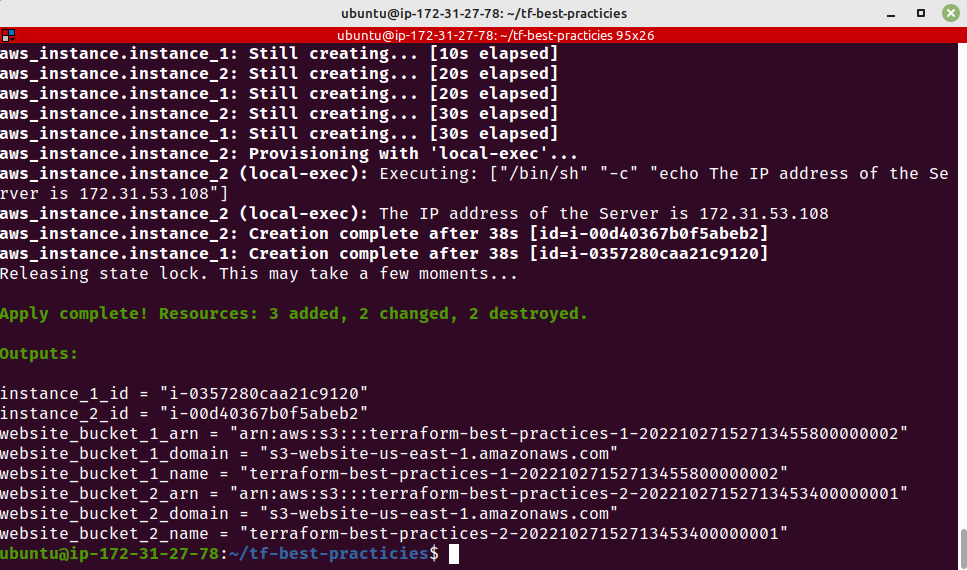
terraform plan -var-file=test.tfvar
terraform apply -var-file="test.tfvars"
Fig. 26 – Instâncias criadas com chave SSH
Podemos ver que as instâncias EC2 que tinhamos antes foram destruídas e novas foram criadas, agora com a informação da chave SSH que deve ser utilizada para acesso.
Fig. 27 – Instância EC2 com chave SSH
Prática 16 – Use Workspaces
Cada configuração do Terraform tem um backend associado que define como o as operações são executadas e onde dados persistentes, como estado, são armazenados
Os dados persistentes armazenados no backend pertencem a um workspace. O back-end inicialmente tem apenas um workspace contendo um estado do Terraform associado a essa configuração. Alguns backends oferecem suporte a vários workspaces nomeados, permitindo que vários estados sejam associados a uma única configuração. A configuração ainda tem apenas um backend, mas você pode implantar várias instâncias distintas dessa configuração sem configurar um novo backend ou alterar as credenciais de autenticação.
Usar vários diretórios é a maneira mais simples de gerenciar várias instâncias de uma configuração com dados de estado totalmente distintos. No entanto, esta não é a técnica mais prática para lidar com diferentes estados.
Quando se trata de preservar diferentes estados para cada coleção de recursos que você gerencia usando a mesma cópia de trabalho para sua configuração e os mesmos plugins e caches de módulos, o Terraform Workspace vem em socorro. Os espaços de trabalho facilitam a transição entre várias instâncias da mesma configuração no mesmo back-end.
Os workspaces nada mais são do que diferentes instâncias de dados de estado que podem ser usados no mesmo diretório de trabalho, o que permite gerenciar vários grupos de recursos não sobrepostos com a mesma configuração. Além disso, você pode usar ${terraform.workspace} para incluir o nome do workspace atual em sua configuração do Terraform.
Digamos que você tenha um projeto do Terraform que provisiona um conjunto de recursos para seu ambiente de desenvolvimento. Você poderá usar o mesmo diretório de projeto para provisionar os mesmos recursos para outro ambiente, controle de qualidade, aproveitando o Terraform Workspace. Você pode até criar um novo workspace e usar o mesmo diretório de projeto do Terraform para configurar outro ambiente. Dessa forma, você terá arquivos de estado diferentes pertencentes a workspaces diferentes para ambos os ambientes.
Dica de sucesso 16:
Use Terraform workspaces para criar múltiplos ambientes como Dev, QA, UAT, Prod, entre outros, usando os mesmos arquivos de configuração do Terraform e salvando os arquivos de estado de cada ambiente no mesmo backend remoto.
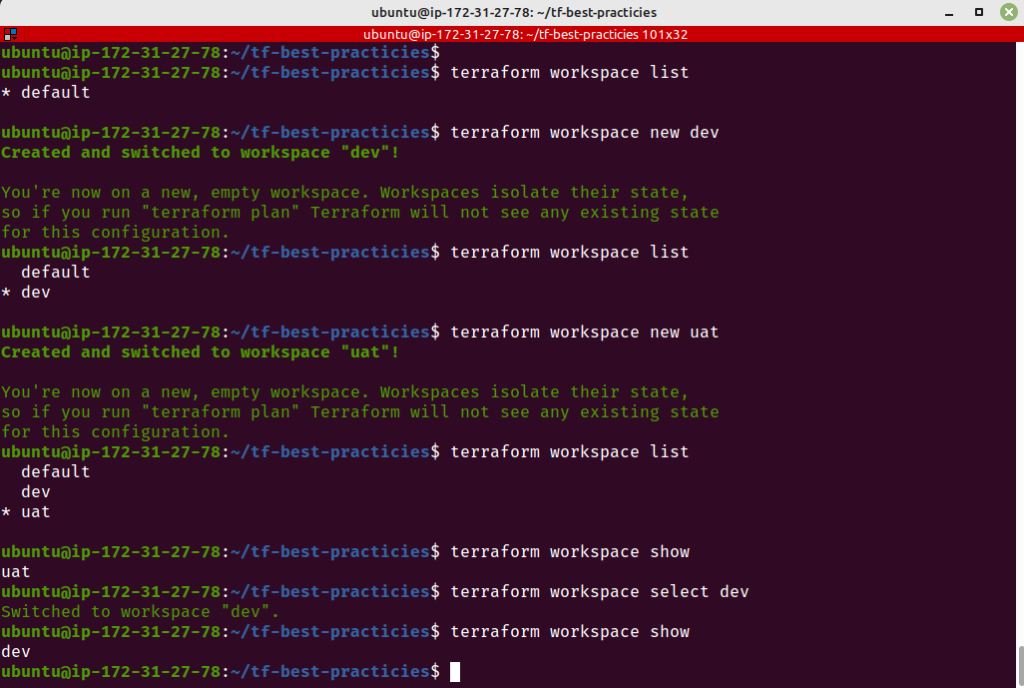
Vamos ver o Terraform Workspaces funcionando em real-time. Execute os seguintes comandos para lista, criar e usar workspaces. Assim que você criar os workspaces, um arquivo de estado diferente para cada um deles será criado dentro do nosso backend remoto (o bucket S3).
terraform workspace list
terraform workspace new dev
terraform workspace list
terraform workspace new uat
terraform workspace list
terraform workspace show
terraform workspace select dev
terraform workspace show
Fig. 28 – Trabalhando com Workspaces
Os comandos vão gerar essa estrutura no S3:
Fig. 29 – Estrutura de Workspaces
Vamos modificar nosso main.tf e utilizar o ${terraform.workspaces} como prefixo para o nome dos recursos. Aproveitaremos para utilizar uma função built-in: format.
No screenshot acima podemos ver que os recursos foram corretamente lançados para cada ambiente e seus nomes possuem como prefixo os nomes dos workspaces.
Prática 17 – Jamais armazene dados sensíveis nos arquivos Terraform
Para gerenciar os recursos do seu ambiente, o Terraform precisa de suas credenciais. Esse é o tipo de informação sensível que deveria ser mantida segura e oculta o tempo todo. AWS access key e secret key, por exemplo, jamais devem ser armazenadas em plain text nos arquivos Terraform, já que os arquivos de estado são armazenados localmente em formato JSON não criptografado. Além disso, outras pessoas com acesso ao seu repositório remoto podem ter acesso a esse tipo de informação. Essa, inclusive, é uma das principais causas de compromentimento de contas em ambiente Cloud que trazem milhões de dólares de prejuízo para as organizações.
Qualquer credencial de acesso ao ambiente cloud (ou onde você for utilizar o Terraform), além de armazenada de maneira segura, deve ser rotacionada de tempos em tempos.
Também não devemos armazenar secrets (como por exemplo senhas de bancos de dados) no código Terraform. Ao invés disso, devemos armazená-las em algum sistema de gerenciamento de secrets, como HashiCorp Vault, AWS Secrets Manager e AWS Param Store antes de referenciá-las.
Como podemos ver no exemplo abaixo, usuário e senha do banco de dados estão armazenados de maneira legível no código Terraform. NÃO FAÇA ISSO!
resource "aws_db_instance" "my_example" {
engine = "mysql"
engine_version = "5.7"
instance_class = "db.t3.micro"
name = "my-db-instance"
username = "admin" # DO NOT DO THIS!!!
password = "admin@123Password" # DO NOT DO THIS!!!
}
Ao invés de escrever informação sensível nos arquivos Terraform, utilize um gerenciador de credenciais e referencíe-o.
resource "aws_db_instance" "my_example" {
engine = "mysql"
engine_version = "5.7"
instance_class = "db.t2.micro"
name = "my-db-instance"
# Let's assume you are using some secure mechanism
username = "<some secure mechanism like HashiCorp Vault, AWS Secrets Manager, AWS Param Store, etc>"
password = "<some secure mechanism like HashiCorp Vault, AWS Secrets Manager, AWS Param Store, etc>"
}
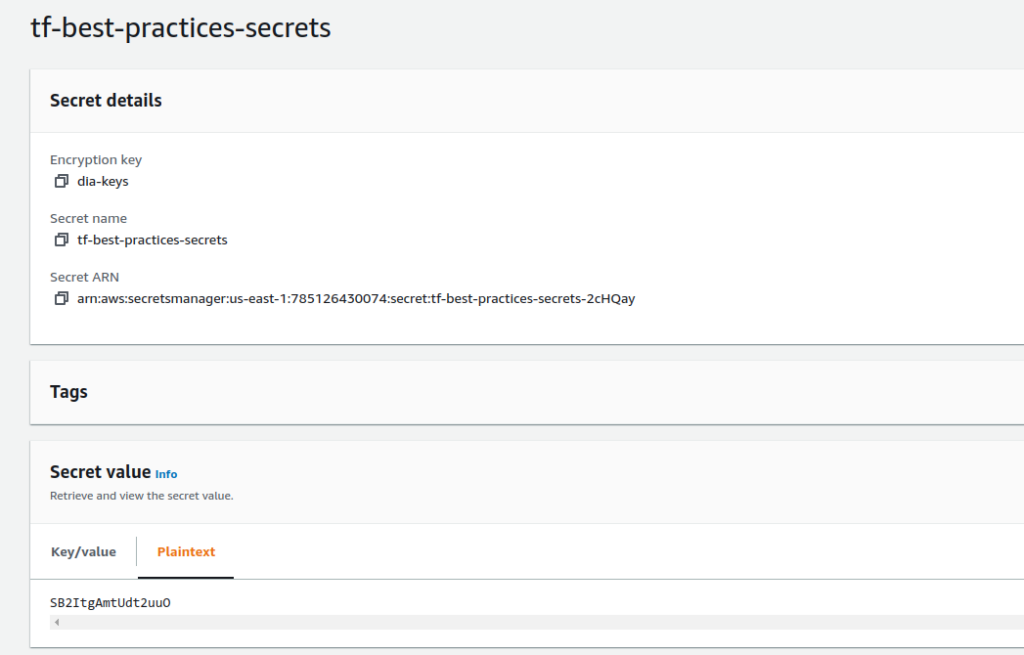
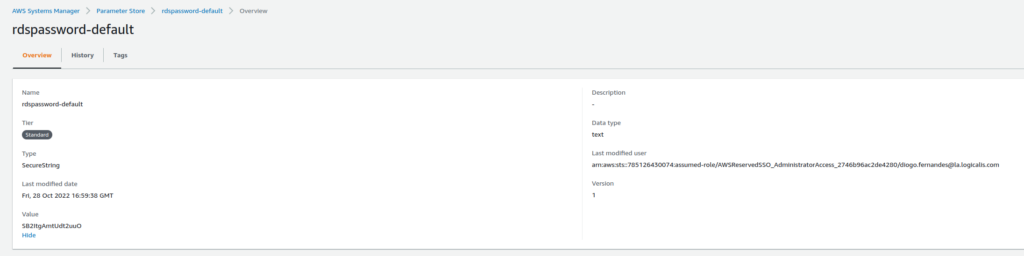
Vamos exemplificar a criação de um recurso seguro de senha, que será armazenada no AWS Secrets Manager.
Como estamos utilizando um novo módulo de Terraform, o módulo random, temos que reinicializar nosso .terraform. Execute os comandos a seguir.
terraform init -upgrade
terraform plan -var-file=test.tfvars
terraform apply -var-file=test.tfvars
Fig. 35 – Senha armazenada no Secrets ManagerFig. 36 – Senha armazenada no Parameter Store
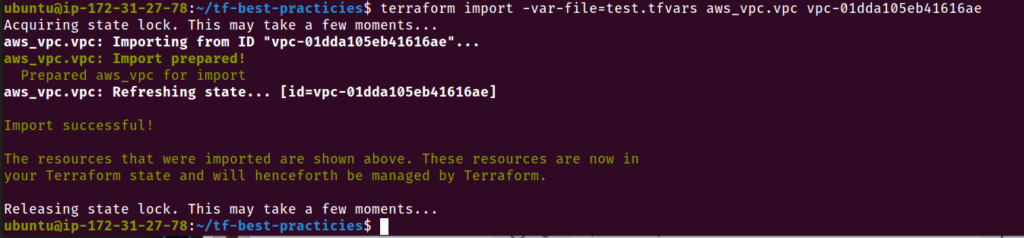
Prática 18 – Use terraform import
O comando terraform import permite trazer recursos que foram provisionados com outro método para a administração do Terraform. Essa é uma excelente técnica para migrar gradualmente a infraestrutura para o Terraform ou para garantir que você possa utilizar o Terraform no futuro. Para importar um recurso, você deve criar um bloco de recursos para ele em sua configuração e dar a ele um nome que o Terraform reconhecerá.
Dica de sucesso 18:
Mesmo que você tenha recursos provisionados manualmente, importe-os para o Terraform. Dessa forma, você poderá usar o Terraform para gerenciar esses recursos no futuro e ao longo de seu ciclo de vida.
Para este exercício vamos criar na AWS um recurso de maneira manual, que será depois importado para o nosso Terraform.
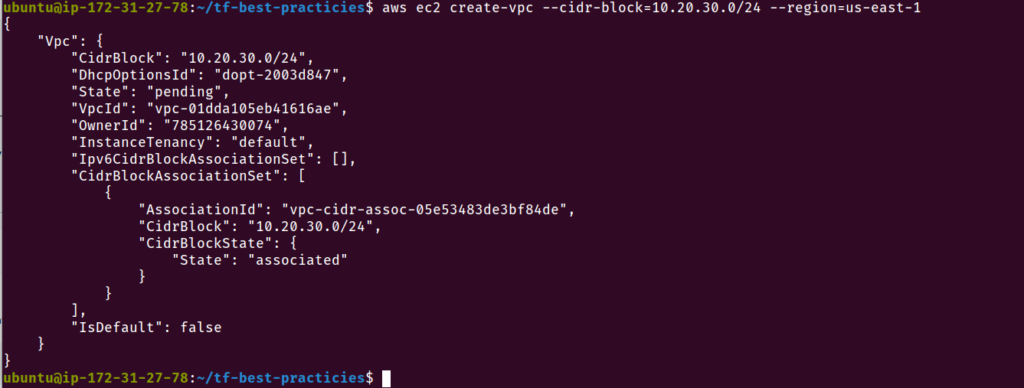
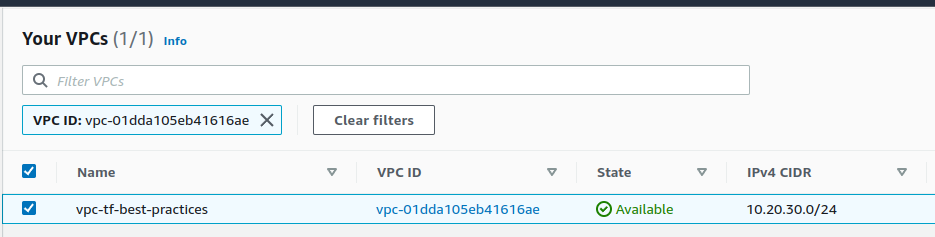
Podemos notar que a VPC que criamos usando aws-cli não possui a tag name. Vamos executar o nosso código Terraform e atualizar o recurso
terraform apply -var-file=test.tfvars
Fig. 39 – VPC gerenciada pelo Terraform
Prática 19 – Automatize seu deploy com CI/CD
O Terraform automatiza várias operações por conta própria. Mais especificamente, ele gera, modifica e versiona seus recursos. O uso do Terraform no pipeline de Integração Contínua/Implantação Contínua (CI/CD) pode melhorar o desempenho da sua organização e garantir implantações consistentes, mesmo muitas equipes usá-lo localmente.
A execução do Terraform localmente implica que todas as dependências estejam em vigor: o Terraform está instalado e disponível na máquina local e os provedores são mantidos no diretório .terraform. Este não é o caso quando você migra para pipelines sem estado. Uma das soluções mais frequentes é usar uma imagem do Docker com um binário do Terraform.
O Terraform pode ser executado em um ambiente de contêiner com arquivos de configuração montados como um volume do Docker após a construção do ambiente. As equipes de desenvolvimento podem usar o fluxo de trabalho de integração contínua para automatizar, fazer autoteste, produzir rapidamente, clonar e distribuir software. Você pode limitar o número de problemas que ocorrem à medida que as implantações migram entre ambientes incorporando a criação e a limpeza do ambiente em seus pipelines de CI/CD. Dessa forma, visto que sua infraestrutura está documentada, sua equipe pode se comunicar, revisar e implantá-la utilizando pipelines automatizados em vez de orquestração manual.
O Terraform define infraestrutura como código (IaC), portanto, não há motivo para não seguir as melhores práticas de desenvolvimento de software. Validar as mudanças planejadas na infraestrutura, testar a infraestrutura no início do processo de desenvolvimento e implementar a entrega contínua faz tanto sentido para a infraestrutura quanto para o código do aplicativo. Em nossa opinião, a integração Terraform e CI/CD é uma das melhores práticas obrigatórias do Terraform para manter sua organização em funcionamento.
Em conjunto com Terraform Workspaces, um pipeline CI/CD com Terraform pode ser capaz de lançar a infraestrutura em um ambiente de testes, aguardar um retorno de testes automatizados e então lançar a infraestrutura no ambiente produtivo, por exemplo.
Por fim, como você armazenará o código do Terraform em sistemas Source Code Management (SCM) ao implementar CI/CD. Aqui estão alguns pontos para ajudá-lo a decidir se você deve manter o código do Terraform no mesmo repositório que o código do aplicativo ou em um local separado, como um repositório de infraestrutura.
O Terraform e o código do aplicativo são combinados em uma unidade, o que facilita a manutenção por uma única equipe.
Se você tem uma equipe de infraestrutura especializada, um repositório separado para infraestrutura é mais conveniente, pois é um projeto independente.
Quando o código de infraestrutura é armazenado com o código do aplicativo, pode ser necessário usar regras de pipeline adicionais para separar os gatilhos das seções de código. Dito isso, em alguns casos, modificações no programa ou no código de infraestrutura acionarão a implantação.
Dica de sucesso 19:
Decida se deseja armazenar a configuração do Terraform em um repositório separado ou combiná-la com o código do aplicativo e ter um pipeline de CI/CD para criar a infraestrutura.
Prática 20 – Mantenha-se atualizado
A comunidade de desenvolvimento do Terraform é bastante ativa e novas funções estão sendo lançadas regularmente. Quando o Terraform lançar uma nova função importante, sugerimos que você comece a trabalhar com a versão mais recente. Caso contrário, se você pular várias versões principais, a atualização se tornará bastante difícil.
Dica de sucesso 20:
Sempre atualize sua versão e código quando major releases do Terraform forem lançadas.
Prefira uma instalação do Terraform através do seu gerenciador de pacotes predileto ou execute sempre o comando terraform version. Se sua versão está desatualizada, um alerta será mostrado.
Prática 21 – Sempre fixe a versão do Terraform e do provider
O bloco terraform{} é usado para configurar comportamentos do próprio Terraform, como configurar o Terraform Cloud, configurar um back-end do Terraform, especificar uma versão do Terraform necessária e especificar os requisitos do provedor.
Como a funcionalidade do provedor pode mudar com o tempo, pois cada plug-in de um provedor tem seu próprio conjunto de versões disponíveis, cada dependência de provedor que você definir deve ter uma restrição de versão especificada no argumento version para que o Terraform possa escolher a versão compatível com seu código. Embora o Terraform aceite qualquer versão do provedor como compatível se o argumento version não estiver incluído (ele é opcional), recomendamos que você forneça uma limitação de versão para cada provedor do qual seu módulo depende e especifique uma versão do provedor como uma das as Melhores Práticas do Terraform.
Para a versão do Terraform, o mesmo vale. Para determinar quais versões do Terraform podem ser usadas com sua configuração, o parâmetro required_version aceita uma string de restrição de versão. Assim, se a versão atual do Terraform não estiver de acordo com as limitações estabelecidas, um erro será gerado e o Terraform será encerrado sem realizar mais atividades. Portanto, definir a versão do Terraform também é muito importante.
Dica de sucesso 21:
Sempre configure a versão de um provedor no required_providers e a versão do Terraform com required_version no bloco de configurações terraform{}.
O código abaixo mostra um exemplo de configuração do Terrafom com a versão do provedor na 4.16.x e a versão do Terraform na 1.2.0
O objetivo de construir uma infraestrutura como código (IaC) com o Terraform é gerenciá-la e implantá-la com confiabilidade, utilizando as melhores práticas. Para identificar e resolver problemas o mais cedo possível no processo de desenvolvimento, o comando terraform validate verifica os arquivos de configuração em um diretório, referindo-se exclusivamente à sua configuração.
Independentemente de quaisquer variáveis especificadas ou estado atual, o processo de validação executa verificações para garantir que uma configuração seja internamente coerente e sintaticamente correta.
Portanto, recomendo que você desenvolva o hábito de executar o comando terraform validate com frequência e antecedência ao criar suas configurações do Terraform, pois é mais rápido e requer menos entradas do que executar um plano.
Dica de sucesso 22:
Sempre execute o comando terraform validate enquanto estiver escrevendo os arquivos Terraform e transforme isso em um hábito para identificar e corrigir problemas o mais cedo possível em seu código.
Execute o seguinte comando:
sed -i "13d" main.tf
Esse comando vai apagar a linha 13 do nosso arquivo main.tf. Vamos validar o código.
terraform validate
Fig. 40 – Erro do terraform validate
As mensagens de erro do Terraform são bastante elucidativas e, em geral, dizem exatamente onde está o problema e qual é ele. Neste caso, não há a chave fechando o bloco de configuração que começa na linha 6 do main.tf (que foi removido quando apagamos a linha 13).
Use o git para fazer o arquivo voltar ao seu estado antes do sed aplicado a ele e valide novamente o código.
git stash
terraform validate
Fig. 41 – Validando um código íntegro
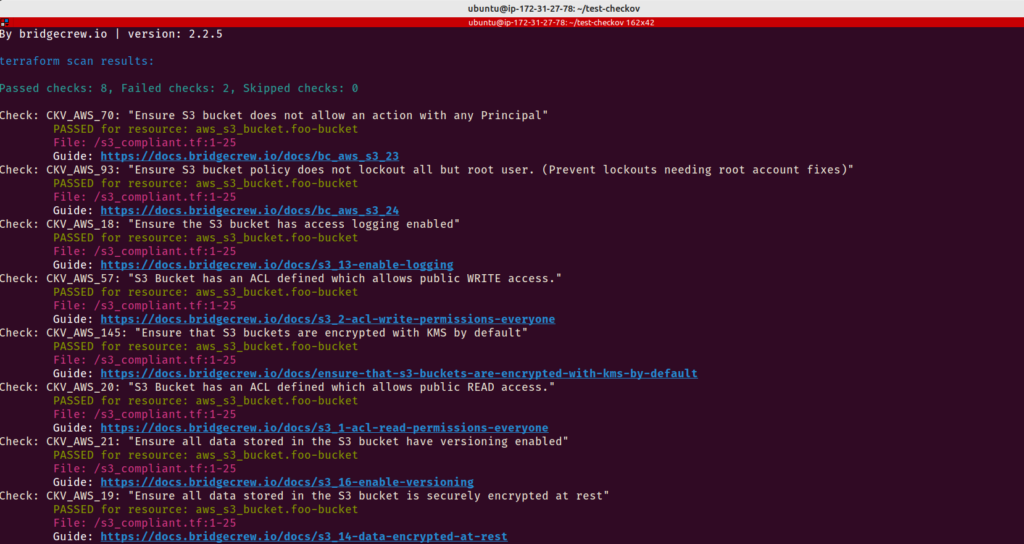
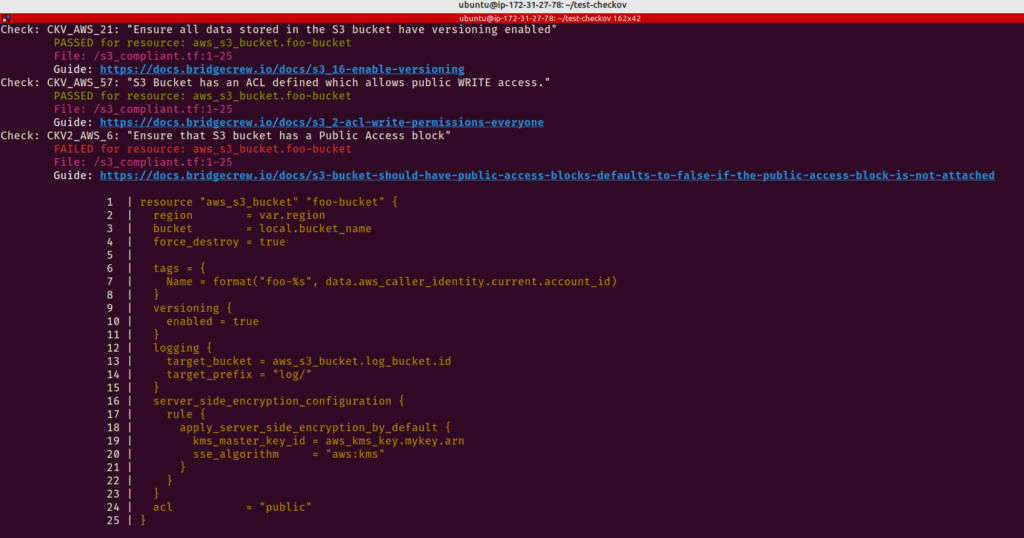
Prática 23 – Use Checkov para analisar seu código Terraform
As configurações incorretas e a falta de boas práticas durante o desenvolvimento dos modelos do Terraform usados para criar a infraestrutura representam sérias preocupações porque a segurança é um componente essencial de todas as estruturas de arquitetura de nuvem. E é aqui que Checkov entra em cena para salvar o dia.
Checkov é uma ferramenta de análise de código estático para verificar a infraestrutura como arquivos de código (IaC) ou seus arquivos de configuração do Terraform quanto a erros de configuração que podem causar problemas de segurança ou conformidade. Checkov tem mais de 750 regras pré-configuradas para procurar problemas típicos de configuração incorreta. Depois de usar o Checkov para escanear todo o código do Terraform, você poderá ver quais testes foram bem-sucedidos, quais não foram e o que você pode fazer para corrigir os problemas.
Dica de sucesso 23:
Você deve testar seu código Terraform da mesma maneira que você testaria qualquer outro tipo de código. É altamente recomendado utilizar ferramentas como o Checkov.
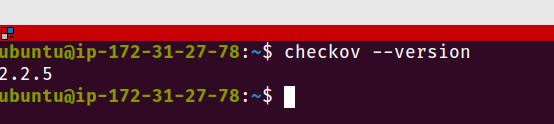
Vamos efetuar a instalação do Checkov, usando o método do pip3. Para outras formas de instalar, consulte a documentação do produto.
sudo pip3 install checkov
checkov --version
Fig. 42 – Checkov instalado corretamente
Vamos agora construir dois blocos de configuração que serão avaliados pelo Checkov.
Como exercício, analise o código que temos no diretório tf-best-practices. Tente corrigir os problemas encontrados.
Prática 24 – Use tflint para encontrar possíveis erros e reforçar o uso de melhores práticas
O TFLint é um linter (ferramenta para melhoria de código) que examina o código do Terraform em busca de possíveis erros, práticas recomendadas, etc. Antes que ocorram erros durante a execução do Terraform, ele também ajudará na identificação de problemas específicos do provedor. O TFLint auxilia os principais provedores de nuvem na identificação de possíveis problemas, como tipos de instância ilegais, alertas sobre sintaxe obsoleta ou declarações desnecessárias e impõe práticas padrão e regras de nomenclatura. Portanto, é importante e recomendado testar seu código Terraform o TFLint.
Dica de sucesso 24:
Para verificar possíveis erros no código Terraform e aplicar as práticas recomendadas, considere um linter como o TFLint.
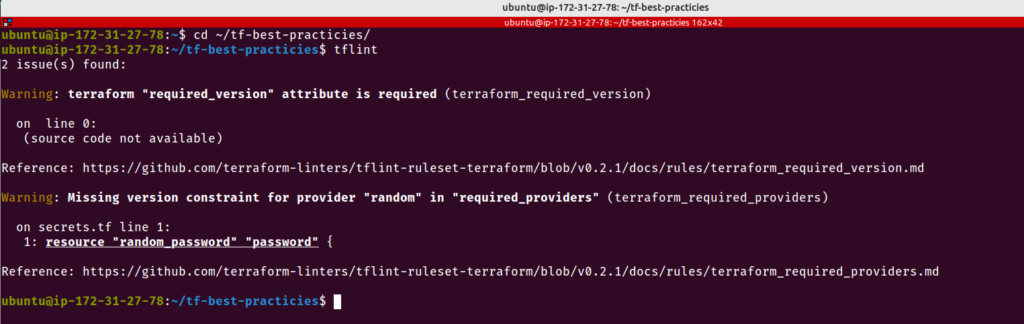
Vamos correr o TFLint em nosso código e ver que tipo de recomendação ele nos fornece.
cd ~/tf-best-practices
tflint
Fig. 46 – TFLint detectando problemas
O TFLint detectou que não estamos seguindo a prática 21, de sempre fixar as versões dos nossos provedores.
Prática 25 – Sempre utilize execution plan files
O comando terraform plan cria um plano de execução, que permite visualizar as alterações que o Terraform planeja fazer em sua infraestrutura. Por padrão, quando o Terraform cria um plano, ele:
Lê o estado atual de qualquer objeto remoto já existente para garantir que o estado do Terraform esteja atualizado;
Compara a configuração atual com o estado anterior e observa quaisquer diferenças;
Propõe um conjunto de ações de mudança que devem, se aplicadas, fazer com que os objetos remotos correspondam à configuração.
O comando plan sozinho não executa as alterações propostas. Você pode usar esse comando para verificar se as alterações propostas correspondem ao que você esperava antes de aplicar as alterações ou compartilhar suas alterações com sua equipe para uma revisão mais ampla.
Se você estiver usando o Terraform diretamente em um terminal e espera aplicar as alterações propostas pelo Terraform, você pode, alternativamente, executar o terraform apply diretamente. Por padrão, o comando apply gera automaticamente um novo plano e solicita sua aprovação.
Você pode usar a opção opcional -out=FILE para salvar o plano gerado em um arquivo no disco, que pode ser executado posteriormente passando o arquivo para terraform apply como um argumento extra. Este fluxo de trabalho de duas etapas destina-se principalmente ao executar o Terraform em um pipeline de IaC. Utilizar um plano salvo em um arquivo garante que o que o plano especulativo mostrou é o que será efetivamente executado pelo Terraform e criado em nossa infraestrutura.
Se você executar o plano terraform sem a opção -out=FILE, ele criará um plano especulativo, que é uma descrição do efeito do plano, mas sem qualquer intenção de realmente aplicá-lo.
Recomendo que o arquivo que armazena o plano em disco seja nomeado como tfplan. O arquivo .gitignore da Prática 2 já o contempla e evita que ele seja versionado e enviado para o repositório remoto, já que esse arquivo pode conter informações sensíveis sobre nossa estrutura.
O comando terraform destroy, embora gere um plano de destruição, não aceita a opção -out=FILE. Devemos usar o comando terraform plan com -out=FILE e -destroy.
Dica de sucesso 25:
Sempre crie um arquivo de plano de execução para ações de apply ou destroy. Um arquivo de plano de execução garante que as mudanças validadas sejam as mesmas que serão aplicadas, além de permitir que o plano de execução seja revisto e validado por outras pessoas.
Vamos criar um plano de execução, salvá-lo em disco e utilizá-lo para lançar nossa infraestrutura.
terraform plan -out=tfplan
terraform apply tfplan
Fig. 47 – Terraform plan com arquivo em disco
Para destruir a infraestrutura criada, executamos os comandos abaixo.
terraform plan -out=tfplan -destroy
terraform apply tfplan
Prática 26 – Use e abuse do pre-commit
Durante o fluxo diário de trabalho, onde estamos criando nosso código Terraform, testando-o, validando a infraestrutura criada, em um ou mais projetos simultâneos, podemos esquecer de seguir alguma boa prática, de fazer algum check de segurança ou de sintaxe que depois podem quebrar nosso pipeline ou mesmo nossos ambientes. Para não nos preocuparmos com esses esquecimentos, podemos automatizar verificações durante um processo que sempre fazemos: o commit (lembrem-se: quem não faz commit não está trabalhando), utilizando hooks.
Os hooks de Git são úteis para identificar problemas simples antes do envio para revisão de código. Podemos executá-los em cada commit para apontar automaticamente problemas no código, como falta de ponto e vírgula, espaços em branco à direita e instruções de depuração. Ao apontar esses problemas antes da revisão do código, isso permite que um revisor de código se concentre na arquitetura de uma mudança, sem perder tempo com detalhes triviais de estilo. Entretanto, a cada novo projeto temos que compartilhar os scripts de hook que desenvolvemos, e podemos incorrer em falhas de versões dos scripts, esquecimento de algum deles, entre vários outros problemas do trabalho mental que se torna manual. Para automatizar a automação, foi criado o pre-commit.
O pre-commit é um gerenciador de pacotes sem dependência de linguagem para hooks de commit. Você especifica uma lista de hooks desejados e o pre-commit gerencia a instalação e execução de qualquer hook escrito em qualquer linguagem antes de cada commit. Seu uso é simples e eficaz.
Vamos instalar e configurar o pre-commit, que foi escrito em Python e, portanto deve ser instalado como qualquer outro pacote ou biblioteca Python
Em um projeto Python, podemos instalar pre-commit em nosso virtualenv colocando uma referência ao pacote no requirements.txt.
Agora, estando no diretório raiz de nosso projeto, crie um arquivo de configuração chamado .pre-commit-config.yaml, ou crie uma configuração básica com o seguinte comando:
Com essa configuração básica, podemos instalar os hooks.
pre-commit install
Com essa configuração básica, os hooks indicados no arquivo de configuração serão executados e validarão o código antes de registrá-lo no banco de dados da cópia local do Git.
Nosso amigo Anton Babenko escreveu vários hooks para validar código Terraform e os disponibilizou em um repositório GitHub, de forma que possa ser utilizado no pre-commit. Para isso, editamos nosso .pre-commit-config.yaml:
Instalamos os hooks de Anton Babenko e vamos utilizar os scripts que formatam nosso código Terraform, geram a documentação de nossos módulos e resources, validam a sintaxe do código e verificam-no nas questões de segurança e misconfiguration, com Checkov. Com isso, sempre enviaremos um código limpo e validado para nosso repositório remoto, nossos pipelines e nossos ambientes.
Como ganho adicional, agora podemos ter nossa biblioteca de configuração de pre-commit e manter o arquivo .pre-commit-config.yaml junto de nosso template de desenvolvimento. Imediatamente após clonar nosso repositório-template, podemos ter um shell-script que o prepara para ser um novo projeto e instalar automaticamente os hooks Git do pre-commit.
Dica de sucesso 26:
Use e abuse dos hooks Git e automatize sua execução com pre-commit. Seu código agradece.
Conclusão
Escrever um código limpo de Terraform não é tão simples quanto parece, mas os benefícios do aprendizado valem o esforço. Este artigo apresentou 25 práticas recomendadas do Terraform que permitirão que você crie um código melhor sem esforço. Essas práticas recomendadas do Terraform ajudarão você desde o momento em que você começar a escrever seu primeiro arquivo Terraform para provisionar a infraestrutura em qualquer uma das plataformas de nuvem com suporte.
Seguir essas práticas recomendadas do Terraform garantirá que seu código do Terraform seja limpo e legível e esteja disponível para outros membros da equipe em um sistema de gerenciamento de código-fonte. Os membros de sua equipe poderão contribuir e reutilizar o mesmo código. Algumas dessas práticas, como o uso do Terraform Workspace e do Terraform Import, ajudarão você a aproveitar os recursos do Terraform que podem ajudá-lo a implantar uma nova cópia da mesma infraestrutura e importar a infraestrutura existente.
Em uma tentativa de agregar essas boas práticas descritas, tenho um repositório no Github que pode ser utilizado como template de um projeto Terraform, já com remote storage para o state file em S3, devidamente versionado, com locking configurado em DynamoDB. Para contribuir com esse código, leia CONTRIBUTING.md.
Para entrar em contato com o autor, basta mandar um e-mail para mrbits@mrbits.com.br
Clean-up
Ao final deste artigo, vamos enviar eventuais modificações de código para o Github e eliminar recursos que lançamos e que ainda estão em nossa conta AWS.
Sempre mantenha seu código versionado e armazenado em um repositório remoto.
2
Use .gitignore
Sempre tenha um arquivo .gitignore em seu repositório com as regras para evitar que arquivos desnecessários sejam gerenciados pelo versionador.
3
Use uma estrutura de arquivos consistente
Use sempre estruturas consistentes de diretórios e arquivos, não importa o tamanho de seu projeto.
4
Auto-formatação de arquivos Terraform
Sempre use terraform fmt -diff para verificar e formatar seus arquivos Terraform antes de enviá-los ao repositório remoto.
5
Evite valores hard-coded
Sempre defina variáveis, atribua valores a elas e as use onde necessitar.
6
Siga sempre uma convenção de nomenclatura
Defina normas e padrões de nomenclatura com seu time e siga-os o tempo todo.
7
Use a variável self
Use a variável self quando você precisa conhecer o valor de uma variável antes do deploy da infraestrutura.
8
Use módulos
Sempre use módulos. Você vai economizar muito tempo de codificação. Não há necessidade de reinventar a roda.
9
Execute terraform com -var-file
Matenha múltiplos arquivos .tfvars com definição de variáveis, que podem ser informados aos comandos terraform plan ou terraform apply através do argumento -var-file.
10
Armazene o arquivo de estado do Terraform em um storage remoto
Quando trabalhamos em um projeto junto a várias outras pessoas, devemos sempre usar backends Terraform que salvam o state file em um armazenamento remoto compartilhado.
11
Bloqueie o arquivo de estado remoto
Sempre use bloqueio de estado quando seu arquivo de estado estiver armazenado em um backend remoto.
12
Faça cópias de segurança do arquivo de estado
Sempre habilite versionamento ou backup do estado remoto do seu Terraform, para que você possa recuperá-lo em caso de acidente.
13
Manipule o arquivo de estado somente pelo comando terraform
Sempre manipule o arquivo de estado do Terraform através do comando terraform e evite efetuar mudanças manuais no arquivo.
14
Gere um README para cada módulo desenvolvido
Você deve ter um README consistente e informativo em todos os seus módulos e projetos Terraform.
15
Use e abuse das funções built-in
Use funções built-in do Terraform para manipular valores em seu código Terraform, executar operações matemáticas, entre outras tarefas.
16
Use workspaces
Use Terraform workspaces para criar múltiplos ambientes como Dev, QA, UAT, Prod, entre outros, usando os mesmos arquivos de configuração do Terraform e salvando os arquivos de estado de cada ambiente no mesmo backend remoto.
17
Jamais armazene dados sensíveis nos arquivos Terraform
Mesmo que você tenha recursos provisionados manualmente, importe-os para o Terraform. Dessa forma, você poderá usar o Terraform para gerenciar esses recursos no futuro e ao longo de seu ciclo de vida.
19
Automatize seu deploy com CI/CD
Decida se deseja armazenar a configuração do Terraform em um repositório separado ou combiná-la com o código do aplicativo e ter um pipeline de CI/CD para criar a infraestrutura.
20
Mantenha-se atualizado
Sempre atualize sua versão e código quando major releases do Terraform forem lançadas.
21
Sempre fixe a versão do Terraform e do Provider
Sempre configure a versão de um provedor no required_providers e a versão do Terraform com required_version no bloco de configurações terraform{}.
22
Valide seu código Terraform
Sempre execute o comando terraform validate enquanto estiver escrevendo os arquivos Terraform e transforme isso em um hábito para identificar e corrigir problemas o mais cedo possível em seu código.
23
Use Checkov para analisar seu código Terraform
Você deve testar seu código Terraform da mesma maneira que você testaria qualquer outro tipo de código. É altamente recomendado utilizar ferramentas como o Checkov.
24
Use tflint para encontrar possíveis erros e reforçar o uso de melhores práticas
Para verificar possíveis erros no código Terraform e aplicar as práticas recomendadas, considere um linter como o TFLint.
25
Sempre utilize execution plan files
Sempre crie um arquivo de plano de execução para ações de apply ou destroy. Um arquivo de plano de execução garante que as mudanças validadas sejam as mesmas que serão aplicadas, além de permitir que o plano de execução seja revisto e validado por outras pessoas.
26
Use pre-commit
Use e abuse dos hooks Git e automatize sua execução com pre-commit. Seu código agradece.
Embora seja tecnologia antiga (o FreeBSD já implementava algo similar em sua versão 4.0, em 2000, chamado Jails), somente nos últimos 6 anos (este texto foi escrito em 2020) vimos a popularização do uso de containers para o deploy de ambientes homogêneos de aplicações, garantindo que tanto Desenvolvimento quanto QA e Produção estejam exatamente iguais em termos de pacotes necessários para se rodar a aplicação, crescer. Mas esse crescimento não pode ser considerado lento. Foi uma explosão.
Uma das vantagens do uso de containers é o isolamento total do seu ambiente operacional de forma que se um atacante consegue comprometer esse ambiente bastará destruí-lo e lançar outro com a vulnerabilidade corrigida, sem necessidade de se lançar uma nova instância ou VM e repetir toda a sua configuração.
Surgiu então o DockerHub, onde as companhias produtoras de sistemas operacionais (mesmo das distribuições linux) lançaram suas imagens, menores e otimizadas. Desenvolvedores e Sysadmin do todo o mundo começaram a criar suas próprias imagens, à partir das imagens base. Outras pessoas começaram a consumir essas imagens. O uso de containers popularizou-se e surgiram sistemas como CoreOS, RancherOS, Swarm e Kubernetes. E então, as pessoas que produziram imagens para os mais variados usos esqueceram-se delas e elas nunca mais foram atualizadas e sistemas inteiros subiram (e sobem) em instâncias rodando a mais nova versão do Sistema Operacional, com todo o hardening de segurança definido pela empresa aplicado e mesmo assim são utilizadas para mineração de criptomoedas. Onde está o problema?
Várias pessoas assumem que uma imagem Docker e seus containers são seguros por padrão, o que, infelizmente, não é o caso. Há algumas coisas que afetam a segurança da sua imagem Docker. Quais pacotes estão instalados na imagem, bibliotecas usadas pela sua aplicação ou mesmo a imagem base, todos esses componentes podem introduzir vulnerabilidades na sua aplicação. Vários deles são facilmente detectáveis e de simples correção, entretanto.
Ouvi uma frase em um evento da IBM onde o apresentador disse que “o DockerHub é a forma mais eficiente de você conseguir uma imagem de container vulnerável” e onde ele mostrava o OpenShift já fazendo um scan automático das imagens e indicando quais eram as suas vulnerabilidades, buscando as bases das principais distribuições Linux e locais como o CVE-Mitre. Mas, se estou utilizando um ambiente como o ElasticBeanstalk da AWS ou um Kubernetes, como faço isso? E se meu pipeline de CI/CD faz build constante da imagem?
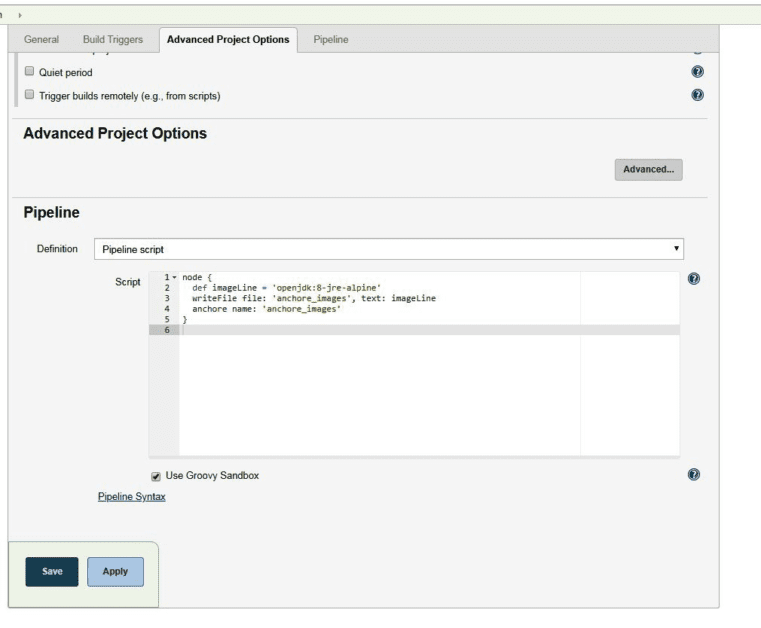
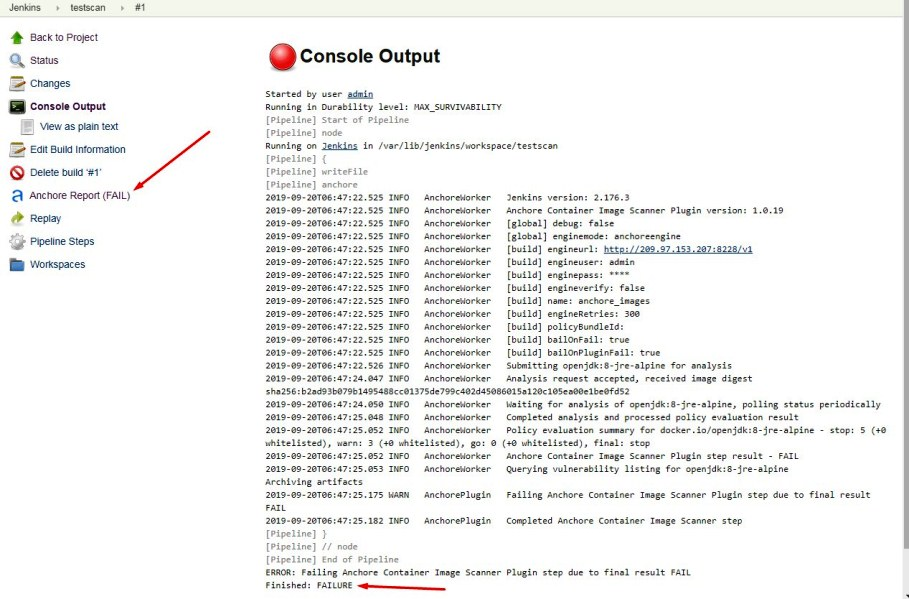
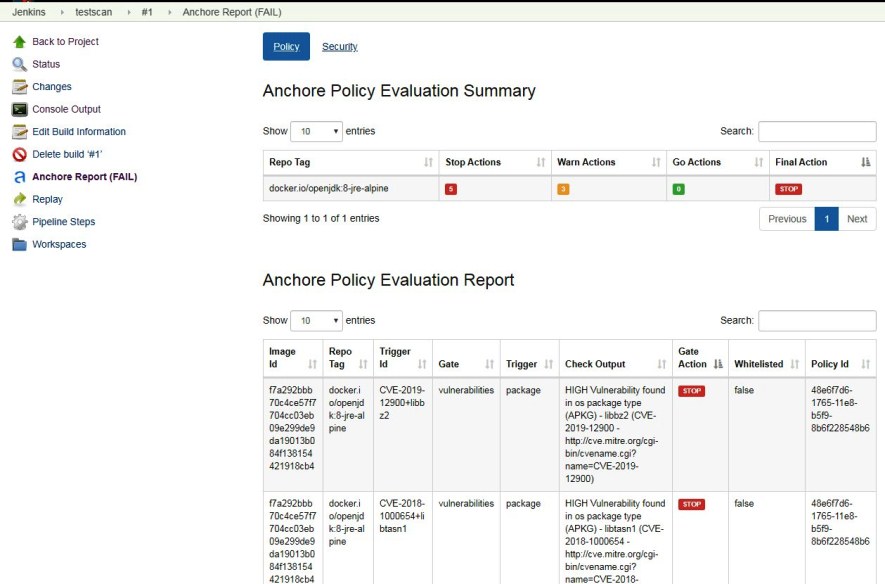
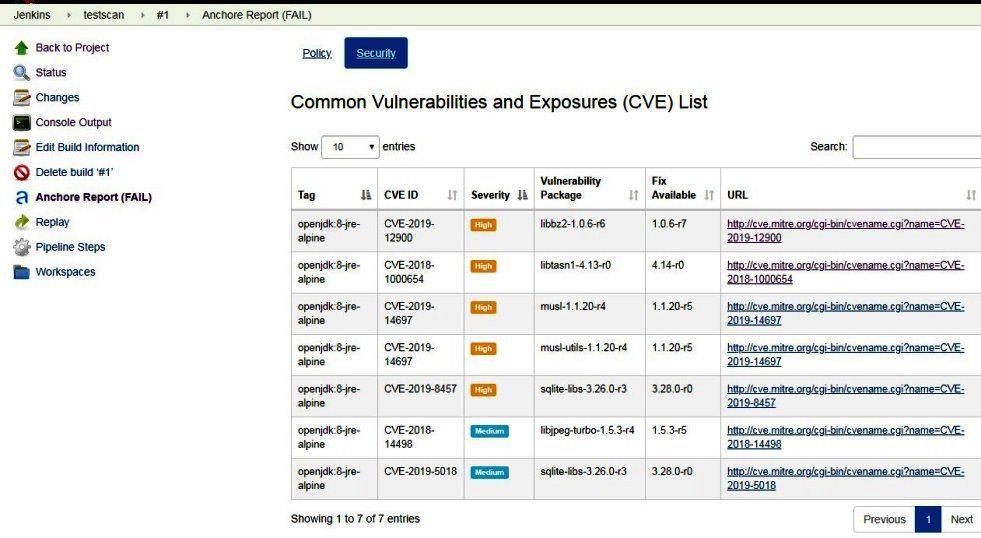
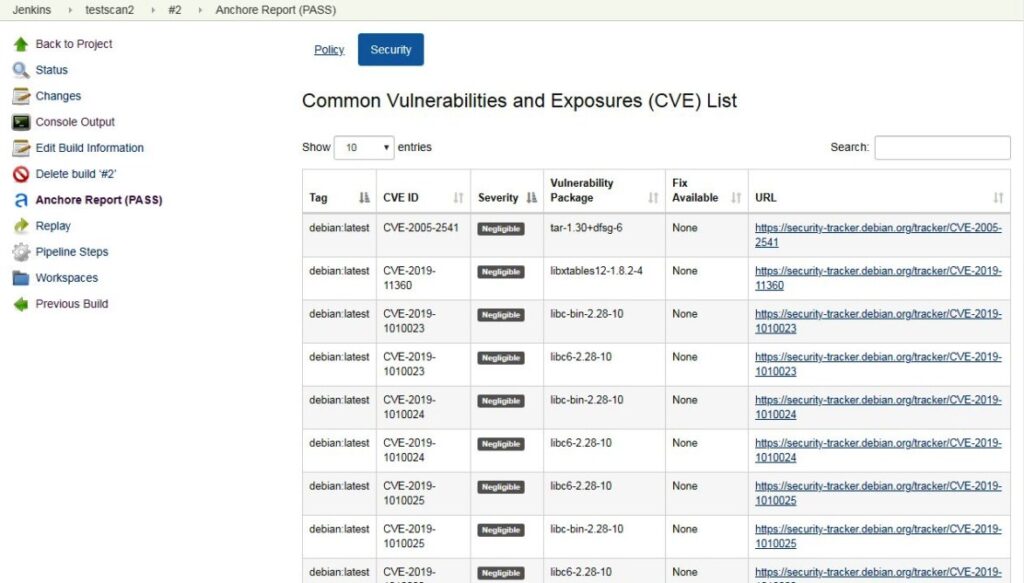
Há uma ferramenta de segurança muito útil que permite que desenvolvedores, times de QA, times de segurança e mesmo Sysop testarem, identificarem e endereçarem vulnerabilidades nas imagens que são usadas para criar aplicações. Chama-se Anchore Engine.
Vamos ver como instalar e usar Anchore Image Vulnerability Scanner a seguir. Geralmente há vários métodos de implementação, mas abordaremos os dois seguintes:
AnchoreCLI command-line;
Jenkins Anchore Container Image Scanner plugin.
Vamos ver como instalar, configurar e iniciar o scanner, configurar e usar a ferramenta de linha de comando AnchoreCLI bem como o plugin para Jenkins. Você aprenderá como adicionar imagens para o scan, executá-lo e ver relatórios.
Ao final deste artigo você terá aprendido o seguinte:
Instalar e configurar o Anchore Engine;
Instalar, configurar e usar o AnchoreCLI;
Configurar e usar o plugin Anchore Container Image Scanner para Jenkins
Para conduzir esse tutorial necessitaremos de uma máquina local ou virtual com Ubuntu 18.04, com Docker, docker-compose e Jenkins instalado e rodando. Recomendo uma instância AWS EC2 t2.medium. Garanta que você tem permissões de sudo ou root nessa máquina.
Configurando e utilizando o Anchore Image Scanner em linha de comando
2 – Configurar o diretório de trabalho e baixar os arquivos de configuração do Anchore.
Crie um diretório de trabalho para os seus arquivos do Anchore. Neste diretório você criará dois sub-diretórios: um para a configuração e outro para a base de dados:
mkdir -p anchore/{config,db}
Acesse o diretório anchore. Faremos o download de dois arquivos de configuração (docker-compose.yaml e config.yaml) à partir do projeto do Github.
O arquivo config.yaml possui as configurações básicas que o serviço de engine do Anchore requer para rodar. Temos vários parâmetros como log level, porta, usuário, senha e todos podem ser ajustados para atender as requisições do sistema.
É uma boa prática de segurança mudar a senha e você pode fazer isso simplesmente editando o arquivo config.yaml. Entretanto, nesse artigo, usaremos as configurações padrão.
Com o diretório de trabalho e arquivos de configuração em seus lugares, o sistema está pronto para a instalação do Anchore.
3 – Instalar e iniciar o Anchore Engine
Usaremos Docker compose para instalar e iniciar o Anchore Engine e seu banco de dados. À partir do diretório anchore faça:
docker-compose up -d
Isto fará o download (pull) das imagens Docker do Anchore automaticamente e criará o seu banco de dados no diretório anchore/database/ previamente criado. Quando completo, o comando iniciará o Anchore engine.
Depois de instalar e iniciar o Anchore com sucesso, você pode analisar imagens Docker usando a ferramenta de linha de comando AnchoreCLI. Naturalmente, você precisa primeiro instalá-la.
4 – Instalar e configurar AnchoreCLI
A ferramenta de linha de comando AnchoreCLI é instalada através do sistema PIP do Python. Primeiro instalaremos o pacote python-pip, que será usada para instalar o AnchoreCLI diretamente do seu código-fonte, já instalando-o e deixando-o pronto para ser configurado de acordo com nosso Anchore Engine.
Em seguida, instale o AnchoreCLI usando python-pip
pip install anchorecli
Este comando executará o download e a instalação dos arquivos do AnchoreCLI. Após a instalação você deve recarregar as suas configurações de profile usando o seguinte comando:
source ~/.profile
Para verificar se a instalação foi efetuada com sucesso, use o comando abaixo para obter a versão do AnchoreCLI:
anchore-cli --version
Para verificar o status do sistema com o AnchoreCLI, use o seguinte comando:
anchore-cli --url http://localhost:8228/v1 --u admin --p foobar system status
Note que você deve passar a URL do Anchore engine, o username e a password.
Por padrão, o AnchoreCLI tentará acessar o Anchore Engine sem autenticação. Entretanto, isso não irá funcionar e então você precisa passar as credenciais para o Anchore Engine a cada comando que você executa. Ao invés disso, a alternativa é definir esses parâmetros como variáveis de ambiente. O comando abaixo definirá a URL do Anchore Engine junto à porta 8228, o usuário e a senha definidos no arquivo de configuração:
Recomendamos manter essas variáveis configuradas nos arquivos .profile ou em seus arquivos de ambientes gerenciados por produtos como autoenv.
5 – Adicionar e analizar imagens
Agora que temos o Anchore Engine rodando e o AnchoreCLI configurado, vamos adicionar e analisar imagens Docker para descobrir vulnerabilidades nelas. Analizaremos duas imagens: openjdk:8-jre-alpine, que possui vulnerabilidades e debian:latest que não as possui. Adicionalmente, analisaremos algumas outras imagens de JDK.
Primeiro, precisamos adicionar imagens ao Anchore Engine. Fazemos com AnchoreCLI, assim:
Após adicionar a imagem ao Anchore Engine, a análise inicia imediatamente. Se há várias imagens carregadas, elas são postas em uma fila e analizadas uma por vez. Você pode verificar o status do progresso e ver a lista de imagens carregadas junto a suas análises. Para ver a lista de imagens, fazemos:
anchore-cli image list
Teremos então a seguinte saída:
mrbits@garganthua:~/anchore$ anchore-cli image list
Full Tag Image Digest Analysis Status
docker.io/openjdk:10-jdk sha256:923d074ef1f4f0dceef68d9bad8be19c918d9ca8180a26b037e00576f24c2cb4 analyzed
docker.io/openjdk:11-jdk sha256:9923c0853475007397ed5c91438c12262476d99372d4cd4d7d44d05e9af5c077 analyzed
docker.io/openjdk:8-jre-alpine sha256:b2ad93b079b1495488cc01375de799c402d45086015a120c105ea00e1be0fd52 analyzed
Dependendo do número de imagens, seu tamanho e tempo passado desde suas adição, você terá o status analyzed para análises completas, analyzing para aquelas em progresso e not analyzed para as imagens aguardando análise na fila.
6 – Visualizar o resultado da análise
Assim que a análise estiver completa, você pode verificar os resultados e ver os dados de vulnerabilidades, avaliação de policy e outros problemas que o Anchore Engine encontrou.
Para verificar os resultados de vulnerabilidades da imagem openjdk:8-jre-alpine faça:
anchore-cli image vuln openjdk:8-jre-alpine all
A saída será algo assim:
mrbits@garganthua:~/anchore$ anchore-cli image vuln openjdk:8-jre-alpine all
Vulnerability IDPackage Severity Fix CVE Refs Vulnerability URL
CVE-2018-1000654 libtasn1-4.13-r0 High 4.14-r0 http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-1000654
CVE-2019-12900 libbz2-1.0.6-r6 High 1.0.6-r7 http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-12900
CVE-2019-14697 musl-1.1.20-r4 High 1.1.20-r5 http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-14697
CVE-2019-14697 musl-utils-1.1.20-r4 High 1.1.20-r5 http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-14697
CVE-2019-8457 sqlite-libs-3.26.0-r3 High 3.28.0-r0 http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-8457
...
O relatório mostra o identificador CVE, o pacote vulnerável, sua severidade e se há ou não uma correção para ela. Para nossa imagem openjdk:8-jre-alpine, a análise mostra que há cinco vulnerabilidades HIGH e mais algumas de níveis médio e não importantes (negligible), que não são mostradas na saída acima.
Para ver as vulnerabilidades de uma imagem estável como a debian:latest, faça:
anchore-cli image vuln docker.io/library/debian:latest all
Como podemos ver pelo relatório, a imagem debian:latest tem vulnerabilidades não importantes e nenhuma correção para elas.
Para ver os resultados da avaliação de políticas para a imagem openjdk:8-jre-alpine, faça:
anchore-cli evaluate check openjdk:8-jre-alpine
Sua saída, cujo resultado mostra uma falha (fail) é:
Image Digest: sha256:b2ad93b079b1495488cc01375de799c402d45086015a120c105ea00e1be0fd52
Full Tag: docker.io/openjdk:8-jre-alpine
Status: fail
Last Eval: 2019-09-20T12:03:32Z
Policy ID: 2c53a13c-1765-11e8-82ef-23527761d060
A imagem viola uma política específica (Policy ID: 2c53a13c-1765-11e8-82ef-23527761d060) e portanto retorna um status de falha.
Agora que vimos como o Anchore Engine responde após detectar uma violação de política, é hora de ver como ele se comporta com a nossa imagem estável debian:latest. Para isso, rodamos o seguinte comando:
Image Digest: sha256:d3351d5bb795302c8207de4db9e0b6eb23bcbfd9cae5a90b89ca01f49d0f792d
Full Tag: docker.io/library/debian:latest
Image ID: c2c03a296d2329a4f3ab72a7bf38b78a8a80108204d326b0139d6af700e152d1
Status: pass
Last Eval: 2019-09-20T12:00:06Z
Policy ID: 2c53a13c-1765-11e8-82ef-23527761d060
Final Action: warn
Final Action Reason: policy_evaluation
Gate TriggerDetail Status
dockerfileinstructionDockerfile directive 'HEALTHCHECK' not found, matching condition 'not_exists' checkwarn
O resultado mostra um status de Pass e uma Final Action como Warn por causa da informação que não não casada com uma diretiva do Dockerfile. Ele não falha, mas requer verificação e tratamento do problema.
Configurando e usando o plugin do Anchore Image Scanner no Jenkins
Testes são parte importante das rotinas de integração contínua e não pode haver deploy em produção se a aplicação não for exaustivamente testada. Entretanto, o que vemos são testes unitários, comportamentais, de integração e regressão sendo feitos, enquanto testes de segurança são relegados a segundo plano.
Nesta parte do artigo trataremos da inclusão de um passo de teste de vulnerabilidades em imagens docker em nosso pipeline, antes da imagem ir para o nosso registry.
7 – Adicionar e configurar o plugin do Anchore Image Scanner no Jenkins
Neste passo, integraremos o Anchore Engine com nosso Jenkins server. Jenkins é um serviço open-source baseado em java para automatização de uma larga gama de tarefas repetitivas no ciclo de desenvolvimento de software.
O plugin do Anchore está disponível no Jenkins mas não é instalado por padrão. Vamos instalá-lo:
Faça login no Jenkins usando um web browser;
Vá ao menu Jenkins;
Localize e selecione Manage Jenkins;
Vá para Manage Plugins;
Na tab Available, role a tela até Build Tools e selecione o plugin do Anchore Container Image Scanner;
Clique em Install without restart option.
Após a instalação do plugin do Anchore Container Image Scanner, o próximo passo é configurar as credenciais. Para isso, siga os passos abaixo:
Vá ao menu Jenkins e selecione a opção Manage Jenkins;
Abra a opção Configure system;
Localize a configuração do Anchore;
Selecione Engine Mode;
Insira os detalhes do Anchore Engine (URL, username, password, e a porta 8228);
Clique em Save.
8 – Adicionar e verificar imagens
Clique em New Item no Jenkins Dashboard no menu à esquerda. Uma janela com várias opções ser abrirá. Insira o nome desejado para o projeto.
Neste projeto usaremos o assistente de Pipeline. Selecione esta opção e clique em OK.
Estamos prontos para verificar nossas imagens. No nosso estudo usaremos as imagens que já estão no registry Docker que é acessível pelo Anchore Engine.
Para isso você deve adicionar ao pipeline o script onde especificaremos a imagem a ser verificada.
9 – Adicionar o script ao pipeline
Role a tela até a seção de Pipeline e adicione o script seguinte para especificar qual imagem deve ser verificada. Começaremos com a openjdk:8-jre-alpineque contém vulnerabilidades.
Isso iniciará o processo de build, que levará alguns minutos, dependendo do tamanho da imagem. Após terminar, um número e um botão colorido aparecerão abaixo da Build History. Ele terá a cor vermelha para Fail ou azul para Pass. Clicar no botão nos mostrará mais resultados.
11 – Verificar os resultados
Clique no Build # para ver mais detalhes. Isso abrirá uma janela de Console Outputindicando uma falha: Anchore Report (FAIL).
Este relatório detalhado indica se a análise falhou (Fail) ou passou (Pass) e nos traz vários dados mostrando as vulnerabilidades, avisos e outros, baseados em nossa configuração. Por padrão o plugin é configurado para falhar e parar um build sempre que haja vulnerabilidades. Abaixo temos um exemplo da tela de relatório de políticas e seguranca.
Abaixo vemos a imagem do relatório de segurança da imagem vulnerável.
Se agora analizamos a imagem debian:latest, sem vulnerabilidades, temos os resultado abaixo, para políticas e vulnerabilidades:
Conclusão
Anchore Container Image Scanner é uma ferramenta de análise poderosa que identifica uma grande quantidade de vulnerabilidades e problemas de políticas em imagens Docker. Possui várias opções de customização e pode ser configurada em como responder quando detecta problemas durante uma análise, como por exemplo a capacidade de falhar o build em um pipeline quando uma vulnerabilidade grave é encontrada.
Esse processo aumentará o tempo de execução do nosso pipeline por adicionar um passo de teste de vulnerabilidades logo após o build, mas teremos a garantia de que nossa aplicação rodará de maneira mais segura do que se esse teste não existisse.
Outras ferramentas
Há várias ferramentas disponíveis para executar análises de vulnerabilidades em imagens Docker. Entre elas podemos citar o Snyk e o Clair.
Da mesma maneira que podemos integrar a análise de vulnerabilidades de imagens docker no Jenkins, é possível fazê-lo facilmente em outras ferramentas. Sua integração com Code Pipeline da AWS é simples e há documentação ampla.
Embora os sistemas de e-mail atuais e mais populares (GMail, Hotmail, Yahoo) implementem sua própria camada de criptografia quando acessamos nossa conta, seja à partir de uma interface web ou seja à partir de um cliente de e-mail como o Thunderbird, não temos certeza de que o tráfego entre um e outro servidor de e-mail esteja criptografado enquanto nossa mensagem é enviada e trafega pela internet, este ambiente hostil e selvagem, cheio de bandidos, totalmente sem lei, sem o qual não vivemos mais. Em minha não tão humilde opinião, da mesma forma como todo e qualquer site deveria rodar única e exclusivamente debaixo de SSL (https), todo e qualquer e-mail deveria ser criptografado.
É muito comum vermos senhas enviadas em e-mails totalmente abertas. Recentemente fiz um cadastro em um site qualquer e recebí a senha que eu havia escolhido exposta no e-mail de confirmação do cadastro. Desconfiado, fiz o processo de recuperação de senha e recebí um outro e-mail que, ao invés de conter um token ou uma URL para que eu pudesse resetar minha senha, recebí aa mesma que eu havia criado antes, abertinha para qualquer papagaio-de-pirata (aquele cara que fica olhando por cima do seu ombro enquanto você está trabalhando) ver e anotar. Além de ter recebido a senha aberta, mostrando que ela fica armazenada desta maneira no banco de dados do tal site, o e-mail também estava aberto, sem nenhum tipo de criptografia, facilitando a vida do nosso papagaio-de-pirata.
Ok, a senha em questão foi gerada unicamente para este site, armazenada no ótimo LastPass, então o risco que eu corria era de ter essa conta desse site comprometida. Mesmo que o site não armazene dados sensíveis demais como um número de cartão de crédito, ainda há lá meu nome, meu CPF, meu e-mail, meu endereço e meu telefone. De posse desses dados, uma pessoa mal-intencionada poderia fazer a festa. Imagine então uma pessoa que usa a mesma senha para todos os cadastros que ela faz! Teríamos aí a senha do Facebook, do Twitter, do Gmail ou Hotmail da pessoa e faríamos uma devassa na vida dela.
Naturalmente, criptografar o e-mail não resolve o problema do site mal desenvolvido que armazena as senhas de seus usuários em plain-text, mas colocaria uma camada de segurança evitando que a senha já tão exposta seja vista por qualquer um que olhe a minha tela.
Vamos então aprender a criptografar nossos e-mails (e outros arquivos que desejarmos) utilizando o sistema chamado GnuPG, uma variação completa do produto aberto OpenPGP, este derivado do PGP de Phill Zimmermann.
O GPG trabalha com um modelo assimétrico de criptografia de dados. Enquanto nos modelos simétricos a mesma chave utilizada para cifrar um texto é utilizada para decifrá-lo, no modelo assimétrico temos duas partes da chave: uma pública (composite) e uma privada (prime factor). Enquanto o texto é cifrado do lado do remetente com a chave pública do destinatário, ela só pode ser decifrada com a chave privada deste. Além disso, as chaves costumam ser grandes, usando um algorítmo RSA com pelo menos 2048 bits, ou 256 Bytes, o que as torna virtualmente inquebráveis pelos modelos computacionais atuais.
Pré-requisitos
Para começar você precisa do GPG instalado em seu computador. É um processo simples em qualquer sistema operacional e vou imaginar que você, leitor, tem domínio do seu a ponto de saber procurar um pacote e instalá-lo, seja num Linux com um gerenciador de pacotes, num MacOS com um brew ou em um Windows baixando o instalador do produto, então não cobrirei a sua instalação.
Operações básicas
Embora seja possível realizar operações mais avançadas com o GPG, inclusive valendo-se de serviços como o Keybase para construir um driver criptografado para seus arquivos e gerenciar sua cadeia de confiança (web of trust), abordaremos neste artigo as seguintes operações:
Criação do par de chaves
Listar chaves
Revogar sua chave
Editar chaves
Compartilhar chaves
Receber chaves
Criptografar uma mensagem
Decriptografar uma mensagem
Assinar uma chave
Confiar em uma chave
Além disso falaremos sobre o conceito de Web of Trust, um dos pilares da comunidade que trabalha ativamente com GPG. Para finalizar, faremos alguns exercícios de casos do mundo real, para fixarmos o aprendizado.
Como hoje todos os sistemas operacionais modernos possuem um shell Unix (Linux com seu Bash, Mac OSX também com Bash e Windows com o excelente Babun ou mais recentemente, para o Windows 10, com o seu Linux Subsystem, virtualmente um Ubuntu com seu Bash), todos os comandos serão executados assumindo que você, leitor, tem acesso a esse shell. Eu, particularmente, uso o ZSH com uma biblioteca chamada Oh My ZSH aqui no meu Linux. Assuma também que todos os comandos são executados com um usuário regular, não privilegiado, do sistema, afinal você quer uma chave pessoal, e não a chave do root do seu computador.
Criação do par de chaves
Para criar seu par de chaves, execute o seguinte comando:
gpg --gen-key
Assim que este comando for executado, ele perguntará que tipo de chave você quer.
Tipos de Chaves
Ficamos com os recomendados RSA com RSA por serem os algorítmos mais fortes que temos. Responda então 1.
A próxima pergunta será o tamanho da chave. Quanto maior a chave, mais tempo levará para alguém fazer um brute force nela, mas mais tempo será necessário para criptografar a mensagem ou o arquivo. Atualmente, como dito antes, uma chave de 2048 bits (256 bytes) oferece segurança suficiente para o nosso dia-à-dia. Se você pode perder alguns mili-segundos a mais criptografando o seu e-mail e queira toda a segurança que o sistema pode oferecer, responda aqui com 4096 (uma chave então de 512 bytes). Se não, responda 2048 e estamos bem.
Em seguida, seremos questionados quanto à expiração da nossa chave. Você pode responder 0 e dizer que a chave nunca vai expirar, e tudo bem se essa for a sua escolha, mas chaves que expiram periodicamente acrescentam uma camada a mais de segurança à sua informação e são muito bem vistas pela comunidade. Podemos aqui definir nossa expiração em dias, semanas, meses ou anos. Vamos, de qualquer maneira, responder 0 aqui e deixar nossa chave sem uma data de expiração. Vai ser solicitada uma confirmação da nossa escolha, à qual respondemos Y.
O próximo dado que temos que informar é o nosso nome. Em teoria, podemos informar qualquer nome aqui, mas se sua intenção é ter uma identidade que realmente pertença a você e que as pessoas saibam que se um arquivo ou mensagem vieram criptografados ou assinados por você, elas podem confiar nessa informação porque o conhecem. Além disso, se você for participar de uma festa de assinatura de chaves, usar um nickname ao invés do seu nome pode fazer suas chaves não serem assinadas (eu passei por isso no FISL de 2010), afinal não existe M3gaHax0rEL33tLuz3rSec no seu RG, certo? Informaremos então nosso nome real, como consta em um documento válido de identidade.
Seremos questionados sobre o e-mail que será utilizado com a nossa chave. Esse é o nosso ID e será a forma mais simples de acessarmos a chave. Digite seu e-mail e não se preocupe se você utilizar vários. Você pode depois adicionar novos e-mails à esta chave (ou criar novas chaves para cada um dos e-mails que você possuir). A minha chave atual tem vários e-mails meus.
Quer colocar um comentário qualquer na sua chave? Aproveite o próximo campo para isso.
O sistema vai solicitar a confirmação dos dados antes de gerar a sua chave. Essa é a sua última oportunidade de mudar algo, sob pena de ter que começar tudo de novo. Se estiver satisfeito, escolha a opção O.
Se receber uma mensagem dizendo que gpg-agent não está disponível para sua sessão, ignore-a. Então, escolha a senha da sua chave. Essa senha criptografará sua chave privada e será solicitada todas as vezes que você usar essa chave. Escolha sabiamente. Se sua chave privada for comprometida, a pessoa poderá passar-se por você e ler suas informações criptografadas. Lembre-se sempre de XKCD. Já encontrei diversas contas por aí cuja senha era alguma variante de Tr0ub4dor&3.
Nesse momento sua chave será gerada, mas você seguramente receberá uma mensagem assim:
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
Not enough random bytes available. Please do some other work to give
the OS a chance to collect more entropy! (Need 283 more bytes).
Como dito anteriormente, a chave é calculada e gerada baseando-se em números primos. Para que o sistema gere números primos grandes, dados randômicos precisam ser coletados. Isso é feito à partir da execução de processos mais pesados no seu SO, como a leitura de um disco ou o mouse andando aleatoriamente para lá e para cá. Eu gosto de gerar esses dados assim:
find / -type f
Esse comando listará todos os arquivos existentes no seu disco e gerará dados suficientes para a criação da sua chave. Ou, se você tiver um gato, deixe-o passear pelo seu teclado. Gatos são ótimos para gerar eventos aleatórios, computação quântica e anti-gravidade, mas tenha certeza de usar manteiga e não margarina para isso.
Relaxe. Isso leva algum tempo. CUIDADO!!! Essa entropia é gerada por hardware. Se você estiver montando sua chave numa máquina virtual (usando VirtualBox, por exemplo), esse processo poderá levar um tempo infinito, porque o GPG não saberá ler o hardware do host. Então, faça algo assim dentro da sua VM:
for X in $(seq 1 100); do find / -type f -exec ls -l {} \; ; done
Assim que o prompt voltar para você sua chave estará gerada. Mas, onde ela está?
Você vai notar que um diretório chamado .gnupg foi gerado no seu $HOME. Dentro dele você terá os bancos de dados que o GPG usa para armazenar suas chaves:
pubring.gpg
secring.gpg
trustdb.gpg
Esses arquivos são os que compõem o nosso keyring (chaveiro). Nesses arquivos são armazenados respectivamente nossas chaves públicas (e as de outras pessoas), nossas chaves privadas e nossa web of trust, ou as chaves que escolhemos explicitamente confiar. Faça um backup desses arquivos regularmente.
Nosso sistema está pronto para operar com GPG. Vamos agora ler nossa chave.
Listando as chaves
O seguinte comando lista nossas chaves de qualquer tipo:
gpg --list-keys
Se quisermos listar somente as chaves privadas, usamos:
gpg --list-secret-keys
Neste momento, os dois comandos devem gerar a mesma saída, já que somente temos nossa chave no banco de dados do GPG.
Há uma informação importante nesses dados. Se notarmos a linha que diz pub ou sec, dependendo do comando, veremos um dado mais ou menos assim:
pub 2048R/7407765A 2017-09-17
Isso nos informa que nossa chave é uma RSA de 2048 bits, criada em 17 de setembro de 2017 e seu ID é 7407765A.
Revogar sua chave
A comunidade envolvida com GPG e OpenPGP leva muito à sério o cuidado e a validação das informações existentes em uma chave. Possuir uma chave é uma responsabilidade grande e mantê-la atualizada é obrigação constante do seu dono.
Uma das coisas mais importantes é dizer que sua chave não é mais válida. Ela pode ser automaticamente invalidada se a criamos com uma data de expiração, mas caso seja comprometida, precisamos revogá-la. Isso é feito criando e importanto um certificado de revogação.
Para criar seu certificado de revogação, execute o seguinte comando:
gpg --gen-revoke -o email.rev <ID>
Nos será perguntado o motivo da criação do certificado e comentários adicionais, e uma confirmação será pedida. Também será pedida a senha da chave privada. Então o arquivo email.rev será gerado em seu disco. É recomendado que esse arquivo seja salvo em algum outro lugar e até mesmo impresso. Como ele é pequeno, pode ser facilmente digitado.
O certificado de revogação é gerado à partir da sua chave privada, portanto se você não mais a possuir, não poderá revogá-la e ficará com sua chave válida até sua expiração ou para sempre.
ATENÇÃO! Importar o certificado de revogação é irreversível! Uma vez revogada, uma chave não pode voltar à seu estado válido, a não ser que tenhamos um backup dos bancos de dados do GPG. As ações abaixo revogarão a chave gerada anteriormente. Antes de prosseguir, certifique-se de que você tem seu backup do diretório .gnupg.
Gerar o certificado de revogação não significa revogar imediatamente a chave. Para fazer isso você precisa importá-lo, assim:
gpg --import email.rev
A saída desse comando é similar à:
vagrant@vagrant-ubuntu-trusty-64:~$ gpg --import chave.rev
gpg: key 7407765A: "My Real Name <myreal@email.com>" revocation certificate imported
gpg: Total number processed: 1
gpg: new key revocations: 1
gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
Se listarmos a chave, veremos que há agora uma informação de revogação nela:
vagrant@vagrant-ubuntu-trusty-64:~$ gpg --list-keys
/home/vagrant/.gnupg/pubring.gpg
--------------------------------
pub 2048R/7407765A 2017-09-17 [revoked: 2017-09-17]
uid My Real Name <myreal@email.com>
O próximo passo é exportar nossa chave pública e enviá-la para nossa teia de confiança e/ou para um keyserver. Teremos maiores detalhes sobre isso na sessão Compartilhando nossa chave.
Manter seguro o certificado de revogação é tão importante quanto manter nossa chave pública segura, pois ele é a única maneira de dizermos ao mundo que nossa chave não é mais válida e que portanto as pessoas não devem mais confiar nela.
Editando nossa chave
O GPG tem uma interface de linha de comando (CLI) que nos permite executar a edição de vários aspectos de nossa chave. Para acessá-lo, faça:
gpg --edit-key <ID>
Um prompt nos será mostrado:
gpg>
Podemos utilizar o comando help para listar todos os comandos disponíveis.
Uma coisa que podemos fazer neste modo é adicionar uma ID à nossa chave já existente. Imaginemos que temos, além do e-mail myreal@email.com, nosso notsoreal@email.com, e queremos adicioná-lo à mesma chave. No prompt de edição de nossa chave utilizamos o comando adduid:
gpg> adduid
A sessão se parecerá com algo como:
gpg> adduid
Real name: My Not So Real Name
Email address: notsoreal@email.com
Comment:
You selected this USER-ID:
"My Not So Real Name <notsoreal@email.com>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
You need a passphrase to unlock the secret key for
user: "My Real Name <myreal@email.com>"
2048-bit RSA key, ID 7407765A, created 2017-09-17
pub 2048R/7407765A created: 2017-09-17 usage: SC
trust: unknown validity: valid
sub 2048R/D3E70A26 created: 2017-09-17 revoked: 2017-09-17 usage: E
(1) My Real Name <myreal@mail.com>
(2). My Not So Real Name <notsoreal@email.com>
Agora, se alguém enviar um e-mail para notsoreal@email.com, ele poderá ser criptografado com a mesma chave de myreal@email.com.
Diversas outras opções existem na edição das chaves. Se você tiver um backup do banco de dados do GPG, pode testar todas.
Algumas outras opções como a assinatura e a confiança de uma chave pública de outra pessoa serão abordadas adiante neste artigo.
Compartilhando nossa chave
Como o objetivo aqui é fazer parte de uma comunidade onde todos trocam as mensagens de forma segura e criptografada, é interessante compartilharmos nossa chave pública. Podemos fazer isso de duas maneiras:
Exportando nossa chave pública para um arquivo e enviando-a a alguém
Para exportar nossa chave para um arquivo, podemos utilizar o seguinte comando:
gpg -a -o pubkey.txt --export <ID>
O neste caso pode ser nosso e-mail ou o valor hexadecimal que pegamos em nosso list-keys. Esse comando vai gerar (–export) um arquivo (-o) chamado pubkey.txt que é a descarga em ASCII (-a) da nossa chave (ID). Seu conteudo é extenso e parece-se com isso:
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1
mQGiBEK5Z9cRBACYslU9tYfH76zbY7wfi5DQV/CoExvtYZ0sr8tDK/qRqfAZn6F7
V/xNKWU8hXVauPE1AAR+6LvW3OZPzwQwtb+lwaowWp9sX/o5arglwr7Ey3r4H2sx
[...]
-----END PGP PUBLIC KEY BLOCK-----
Envie esse arquivo aos seus amigos. Se eles não souberem o que fazer com isso, envie o link deste artigo para eles.
Enviando nossa chave pública para um servidor de chaves
Existem milhares de servidores espalhados pelo mundo que armazenam chaves públicas e que espalham essas chaves para os outros servidores, formando uma teia redundante onde não importa em qual servidor enviamos nossa chave, ela existirá em todos os outros em poucos segundos.
Para mandar nossa chave para um servidor público, utilizamos o seguinte comando:
pool.sks-keyservers.net é um serviço que contém diversos servidores de chaves e encarrega-se de enviar a sua chave para um deles e, depois, distribuí-la para o mundo. Também podemos usar o pgp.mit.edu, bastante estável e seguro.
Esse comando enviará sua chave pública para esse pool de servidores e ela estará publicada. Nunca mais essa chave será excluída e qualquer pessoa poderá ter acesso a ela.
Recebendo chaves públicas
Se as pessoas com as quais vamos compartilhar informações de maneira criptografada também enviaram suas chaves para um servidor, é possível conseguir essas chaves à partir dele. Você só precisa ter o ID da chave.
Para conseguí-lo, você pode fazer uma busca em alguma ferramenta disponível. Um bom lugar para se procurar é o serviço de chaves do MIT, que fica em . Se você procurar simplesmente por mrbits, vai receber uma listagem de todas as chaves que eu um dia subi para algum servidor de chaves. Várias delas, infelizmente, foram perdidas e não me foi possível revogá-las, mas minha primeira chave data de 30/07/1997. Sou, então, um feliz usuário de criptografia por já 20 anos.
Minha chave válida é a de ID 2B3CA5AB, datada de 19/01/2010. Essa chave nunca foi comprometida e seu certificado de revogação existe e está muito bem guardado.
Para importá-la para o seu keyring, execute o seguinte comando:
O deve ser o valor hexadecimal da chave. No caso da minha, esse valor é 6EC818FC2B3CA5AB e pode ser conseguido na ferramenta de busca de chaves do MIT.
A saida do comando será mais ou menos assim:
gpg: requesting key 2B3CA5AB from hkp server pool.sks-keyservers.net
gpg: key 2B3CA5AB: public key "Diogo Carlos Fernandes (MrBiTs) <mrbits.dcf@gmail.com>" imported
gpg: no ultimately trusted keys found
gpg: Total number processed: 1
gpg: imported: 1 (RSA: 1)
Importamos com isso nossa primeira chave. Se agora executamos um –list-keys, veremos a nossa chave privada e a chave que importamos.
Assinando uma mensagem
Quando as relações de confiança são estabelecidas, podemos enviar um e-mail a alguém que possua nossa chave pública que não precisa ser necessariamente criptografado, mas que pode ser digitalmente assinado. Podemos fazer o mesmo com um arquivo que geramos, de forma que o destinatário possa validar que os dados vêm de uma fonte que ele confia.
Uma assinatura digital certifica e valida o timestamp de um arquivo ou mensagem. Se após sua assinatura ele for modificado, a verificação desta falhará.
Vamos criar um arquivo contendo alguma informação qualquer e chamá-lo de topsecret.txt.
cat >topsecret.txt<__EOF__
Este arquivo é confidencial e contém informações
que somente podem ser lidas por pessoal autorizado.
Aqui vem uma senha
Aqui vem um número de cartão de crédito, sua data
de expiração, seu CVV, nome e tudo o mais que os
bandidos adoram ter em seu poder.
__EOF__
Se vamos trabalhar com mensagens de e-mail, eu prefiro assiná-las em clear sign. Se por outro lado vamos assinar um arquivo (um documento, uma imagem) eu trabalho com assinaturas detached.
O resultado do arquivo topsecret.sig será algo assim:
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA256
Este arquivo é confidencial e contém informações
que somente podem ser lidas por pessoal autorizado.
Aqui vem uma senha
Aqui vem um número de cartão de crédito, sua data
de expiração, seu CVV, nome e tudo o mais que os
bandidos adoram ter em seu poder.
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAEBCAAGBQJZvwmlAAoJEG7IGPwrPKWrieUH/ihHnkmCXA4epbw+h8AjU0wk
6s4Cf7STYnqCtuzR35RSWxe9Jh2HqPfWaJbj3A+CaHMDIVsAwpegiBvBEhPSZgIC
tS0nYPnLUyblAOhalm5vRVqu18Wtq1cNPa+6yy4KIZxeP8xp/Ooc1Nnxe6T2tjnt
Y8/w+mzam3gdxFQIbwq+G6JMLB4J0czIv6Hji7G1S6YOofEC9xT2Q9Qe4TvnZpRT
udvK7V3Y9O3S2MBVYsi2NDNeBnLfapuH8f9nYoK190xz+vPXNjbAITeIAHZ+iNLw
pNrayqVdcMzRbYB5aq6Y7zV5Me0HmvAJfLQkx7J+2OeWtmnDcDPwDHknUjtr3JE=
=I6fH
-----END PGP SIGNATURE-----
Vemos que a mensagem original foi mantida e algumas referências a assinatura digital foram inseridas.
Para verificar a mensagem, executamos:
gpg --verify topsecret.sig
Se o resultado contiver Good signature, então nossa mensagem veio de uma fonte confiável
Assinando arquivos com assinaturas detached
Se temos um arquivo preparado por nós, como por exemplo um documento que queremos enviar mas que não pode ter seu conteúdo modificado com as informações do GPG, podemos assiná-lo com uma assinatura detached. Para isso, executamos
Um arquivo chamado topsecret.sig será criado e deverá ser enviado em conjunto com nosso documento. Para saber se o arquivo é válido e veio de uma fonte confiável, executamos o mesmo –verify, mas agora precisamos informar também o arquivo, além da assinatura:
gpg --verify topsecret.sig topsecret.txt
Novamente a mensagem de Good signature deve aparecer. Se, ao contrário, obtivermos uma Bad signature, então ou a chave com a qual o arquivo foi assinado não é a que temos em nosso keyring ou o arquivo foi modificado de alguma maneira.
Criptografando uma mensagem
Agora, nossa mensagem contém dados sensíveis e que queremos proteger, então devemos criptografá-la. Uma mensagem pode ser criptografada para um ou mais usuários e até mesmo somente para você. Tudo o que vc precisa é ter a chave pública dos usuários importada no seu keyring e saber quais são seus ID que são os e-mails desses usuários.
Para criptografar uma mensagem basta fazer:
gpg -e -a topsecret.txt
O comando pedirá os destinatários da mensagem, um por vez. Após colocar todos, termine com um ENTER. Um arquivo topsecret.txt.asc será gerado, com um conteúdo mais ou menos assim:
Envie este arquivo aos seus destinatários. Eles, de posse de sua (deles) chave privada, serão capazes de ler a mensagem.
É possível também criptografar a mensagem inline. Execute o comando gpg somente com a opção -e. Os destinatários serão pedidos e depois você poderá digitar o texto. CTRL+D mostrará a mensagem criptografada. Copie-a e cole-a no corpo de um e-mail. Não se esqueça das linhas de BEGIN e END.
Decriptografar uma mensagem
E então recebemos uma mensagem criptografada. O e-mail que recebemos de nossa fonte confiável contém o arquivo topsecret.txt.asc.
Basta colocar esse arquivo em seu disco e executar:
gpg -d topsecret.txt.asc
O GPG vai pedir a senha da nossa chave privada e, após digitá-la, leremos a mensagem.
Também podemos decriptografar inline utilizando a opção -d do comando gpg sem passar o arquivo e simplesmente colar o seu conteúdo previamente copiado. Não se esqueça de copiar também as linhas de BEGIN e END. Após digitar a senha, CTRL+D mostrará a mensagem aberta.
Assinar uma chave
Assinar uma chave pública de outra pessoa significa dizer para o mundo que você reconhece, certifica, que a chave pertence a essa pessoa. Assinar uma chave é uma grande responsabilidade e deve ser feita de maneira cuidadosa, após verificar se a chave pertence mesmo à pessoa que a enviou.
Jamais assine uma chave sem verificar seu fingerprint, pelo menos. O fingerprint é uma sequencia de 40 bytes, agrupados em 4 e é uma validação única da chave. O algorítmo que o gera é bastante complexo e evita que exista colisão de fingerprints, assim jamais duas chaves diferentes os terão iguais.
Para validar o fingerprint, peça para o dono da chave que você quer validar que envie a você seus valores junto com a chave pública e execute o seguinte comando:
gpg --fingerprint <ID>
Se o fingerprint mostrado não for igual ao que a pessoa enviou a você, não assine a chave e comunique isto a seu dono. A chave pode ter sido comprometida.
Se o fingerprint estiver correto, você pode assinar a chave pública da pessoa assim:
gpg --sign-key <ID>
Além do fingerprint (e outras informações da chave) serem mostradas, será pedida uma confirmação (Reallly sing (y/N)) e por fim a senha da sua chave privada. Então, estamos assinando uma chave pública com nossa chave privada.
Uma vez assinada a chave, exporte-a e envie-a para um servidor de chaves.
Vale reforçar que assinar uma chave não significa confiar na pessoa, mas somente validar que a chave pertence à pessoa que diz ser seu dono.
Confiando em uma chave
Além de assinar a chave, podemos dizer ao mundo que confiamos na pessoa, que ela é quem diz ser e que informações vindas dela são confiáveis e seguras. Se fizermos um paralelo com os certificados digitais de chaves SSL (https), podemos dizer que a assinatura de uma chave é um certificado do tipo 1, que diz somente que um determinado host ou domínio pertence à pessoa ou empresa que diz possuí-lo, enquanto que confiar em uma chave é como gerar um certificado do tipo EV (extended validation), onde você certifica que a empresa ou pessoa que diz ser dona da chave existe, possui documentos como RG, CPF, Contrato Social, passaporte ou algo do gênero (e se isso não significa nada para você, aguarde meu próximo artigo sobre SSL). Além disso, você pode dizer em qual nível você confia na chave.
Para configurar o nível de confiança de uma chave, execute o seguinte comando:
gpg --edit <ID>
No prompt de gpg>, utilize o comando trust. Informações da chave serão mostradas e os seguintes níveis de confiança poderão ser escolhidos:
1 = Don't know
2 = I do NOT trust
3 = I trust marginally
4 = I trust fully
Dizer que você não sabe ou não conhece a pessoa (1) ou dizer que você não confia na chave (2) são informações úteis para a comunidade que trabalha com GPG. Dizer que confia vagamente (3) quer dizer que você conheceu a pessoa, olhou seus documentos, verificou seu fingerprint mas não tem muita certeza do tipo de informação que pode vir dessa pessoa. Dizer que confia totalmente (4) quer dizer que você validou a pessoa, a chave e ainda garante que os dados vindos dela são confiáveis.
Escolha uma das opções e finalize a edição da chave. Exporte e envie a chave pública para um servidor.
Considerações sobre assinaturas e confiança de chaves
Assinar e confiar em uma chave são ações de grande responsabilidade para a comunidade que trabalha com GPG e para uma perfeita construção de sua Web of Trust. Eu até posso assinar uma chave de uma pessoa que eu não conheço somente validando seu fingerprint, mas para confiar em uma chave eu vou querer sentar-me numa mesa de bar, tomar uma cerveja com essa pessoa, apertar sua mão e olhar seus documentos.
Jamais assine ou confie em uma chave levianamente.
Web of Trust
Embora possamos usar GPG para criptografar nossos arquivos e informações confidenciais, usá-lo somente para isso não é o bastante. Queremos compartilhar informação de maneira segura. Para que essa comunicação ocorra, precisamos ter nossa Web of Trust. Imgine isso como uma rede social onde cada um confia na chave do outro, formando uma rede de confiança onde Zezinho confia na chave de Luisinho, que confia na chave de Huguinho, que confia na chave de Zezinho, que confia na chave de Huguinho.
Huguinho <———-> Zezinho
\ /
\ /
<—>Luisinho<–>
Se adicionamos à nossa rede de confiança o Pato Donald e Huguinho diz que confia em sua chave, como Zezinho e Luisinho confiam em Huguinho, podem confiar no Pato Donald também. Este, por sua vez, por confiar em Huguinho e saber que ele confia nas outras duas pessoas, passa a confiar nelas.
Gerar uma rede de confiança neste nível é trabalhoso. Primeiro, as pessoas que fazem parte dela precisam se comunicar usando GPG. Depois, as chaves precisam ter assinaturas suficientes para serem consideradas válidas. Não são, entretanto, problemas técnicos, mas problemas sociais.
Quando começamos a utilizar GPG é importante ter em mente que não vamos imediatamente nos comunicar de maneira segura com todas as pessoas que nos correspondemos. O ideal é começar com um pequeno grupo de pessoas, talvez você e mais dois ou três amigos que também querer exercer seu direito à privacidade. Gerem suas chaves e assinem e confiem nas chaves públicas uns dos outros. Encontrem-se, troquem fingerprints, bebam uma cerveja e façam sua primeira festa de assinatura de chaves. Está será sua primeira rede de confiança. Ela será robusta e o exercitará nas boas práticas de mantê-la assim quando ela começar a crescer.
Depois, diga aos outros que você usa GPG. Assine seus e-mails e mensagens que você envia para listas de discussão, por exemplo, e logo alguém virá perguntar o que significa aquela assinatura. Coloque também sua chave pública ou o link para seu acesso em um keyserver nesta assinatura e na sua página pessoal. A chave pública chama-se assim pelo motivo óbvio de que deve ser publicada. Quando as pessoas tiverem dúvidas sobre como trabalhar, direcione-as para este artigo.
Quando as pessoas começarem a enviar suas chaves, você vai querer validá-las. Isso é um pouco mais difícil. Se você não conhece a pessoa cuja chave você quer assinar, mandam as boas práticas que você não a assine. Idealmente, procure encontrar a pessoa, tomar um café com ela ou participar de uma festa de assinatura de chaves. Coloque também em seu cartão de visitas a fingerprint da sua chave pública e um QRCode com a URL do servidor onde ela pode ser acessada. Dessa forma, quando você encontrar uma outra pessoa que usa GPG, ela poderá assinar sua chave e você assinará a dela de volta, aumentando a confiança da sua rede.
Tenha em mente que tudo isso é opcional. Você não é obrigado sequer a publicar sua chave em um servidor e pode compartilhá-la somente com as pessoas que você quer efetivamente trabalhar com GPG. Pode escolher jamais assinar uma chave ou sequer querer que sua chave seja assinada. Eu implementei um projeto de GPG em uma empresa onde as chaves públicas eram compartilhadas e assinadas somente internamente e residiam em um versionador de código. A WoT dessa empresa continha apenas seus funcionários. O poder do GPG é que ele é flexível suficiente para adaptar-se às suas necessidades de segurança, quaisquer que sejam elas.
A Festa de Assinatura de Chaves
Apesar do nome, esse evento costuma ser bem calmo e silencioso, e acontece com mais freqüência do que imaginamos. Vários eventos de tecnologia são usados para se organizar uma festa de assinatura de chaves. O FISL todos os anos tem uma.
Nesta festa de assinaturas as chaves públicas são enviadas a um banco de dados pelos seus donos. À partir desta informação é gerada uma planilha contendo Nome, número de um documento e o fingerprint das chaves submetidas. Cada participante, ao chegar na festa, recebe uma cópia impressa com espaços para marcar as chaves efetivamente assinadas.
Durante a festa, cada participante vai até um projetor e coloca o documento que foi informado no formulário de submissão da chave, que deve conter a foto da pessoa. Dê preferência a documentos como RG, CHN ou Passaporte. Documentos sem foto não devem ser aceitos.
O participante então fala seu nome, o número do documento, o ID da chave e o seu fingerprint, e cada pessoa valida as informações da planilha. Se tudo estiver correto, fazemos uma marca na chave que será assinada.
Informações inconsistentes invalidam a chave, que não deve ser assinada.
Ao chegar em sua casa, você pode fazer o download deste banco de dados de chaves e importar todas para o seu keyring. Então, de posse da planilha, assine as chaves válidas e as envie para um servidor de chaves.
Isso ajuda muito a aumentar a confiabilidade da nossa rede.
Ferramentas
Várias ferramentas foram escritas para facilitar a administração do nosso keyring. O Thunderbird possui um plugin chamado OpenPGP Manager que adiciona facilidades de gerenciamento de chaves e assinatura/criptografia dos e-mails ao produto. Todos os ambientes gráficos têm suas ferramentas de gerência de chaves, como o KGPG do KDE. O site do GnuPG contém uma listagem de ferramentas que podemos usar.
Exercícios de operação com chaves
Neste exercício enviaremos nossa chave pública para um servidor, importaremos a minha chave pública de um servidor de chaves, validaremos seu fingerprint, assinaremos e enviaremos novamente a este servidor.
a)Enviando a chave para um servidor
Para enviar sua chave para um servidor, execute o seguinte comando:
Após a execução do comando, valide a importação da chave com
gpg --list-keys
c)Validando o fingerprint
Para extrair o fingerprint da minha chave, use o seguinte comando:
gpg --fingerprint 6EC818FC2B3CA5AB
O fingerprint da minha chave é
29F1 6B05 FCCA C89B 4062 12B4 6EC8 18FC 2B3C A5AB
Valide-o com a chave que você recebeu do servidor no passo a.
d)Assinando a chave
Uma vez que a chave tenha sido validada pelo seu fingerprint, podemos assiná-la. Para isso, execute o seguinte comando:
gpg --sign-key 6EC818FC2B3CA5AB
Novamente há a possibilidade de validarmos o fingerprint da chave. Sua senha será pedida, já que a minha chave pública vai ser assinada com sua chave privada. Uma confirmação deve ser feita.
e)Enviando a chave ao servidor
Para enviar a minha chave pública, agora assinada por você, execute:
Após o sucesso dessa operação o exercício está concluído.
Considerações finais
Segurança de dados é responsabilidade individual de algo coletivo. De nada adianta você receber uma informação em um e-mail criptografado e reenviá-la em texto aberto.
Segurança dá trabalho. É muito mais fácil enviar um e-mail sem criptografia ou ter a mesma senha para o suas contas de e-mail, Facebook, Twitter e sua conta bancária, mas o risco de ter suas informações expostas e sua conta limpa é grande. Difundir segurança é um trabalho ingrato, porque você sempre vai ouvir aquele diretor falar que “nosso cliente não vai perder tempo instalando esse software e tendo que clicar em mais de um botão para abrir o e-mail”. E ele não está errado. A grande maioria das pessoas realmente não vai querer perder tempo com isso. Nada podemos fazer. O que podemos fazer é manter nossa teia de confiança. O que eu faço quando tenho que passar informação sensível é passá-la verbalmente ou pedir à pessoa que vai recebê-la que saiba que está recendo uma informação sensível aberta e que ela é responsável pela segurança dessa informação daí em diante.
Se o leitor tiver dúvidas, críticas ou quiser sugerir correções e melhorias para este artigo, por favor envie-me um e-mail, criptografado, naturalmente.
Uma ferramenta que facilita a criação de clusters Kubernetes na AWS é o KOPS. Os passos à seguir mostrarão como instalá-lo e utilizá-lo para montar seu cluster. Como leitura adicional, recomendo o Starting Guide
Pré requisitos
Verifique se você possuí suas credenciais da AWS no seu arquivo .aws/credentials. Você precisará de permissões em EC2 e Route53.
Crie um domíniou ou subdomínio no Route53 de sua conta AWS. O KOPS não irá funcionar se você não possuir um domínio público gerenciado pelo Route53.
Determine uma faixa de IP para usar em sua nova VPC (ou escolha uma VPC existente). Para clusters temporários ou pessoais, eu costumo usar 10.0.0.0/16.
Instalando KOPS
Para a instalação do KOPS em MAC OS-X, você precisa ter brew instalado antes.
Escolha uma região da AWS para construir seu cluster. Nos exemplos abaixo eu escolhi us-west-1. Veja quantas AZ a região escolhida possui e defina um CIDR para as subnets que serão criadas em cada uma dessas AZ. Como us-west-1 possuí duas zonas utilizáveis (us-web-1b e us-west-1c), criarei subnets /22 para elas. Precisamos também ter o par de chaves SSH que permitirá acesso aos hosts do cluster armazenados em nossa máquina. Esse par de chaves pode ter sido criado no próprio painel da AWS, caso em que você precisará extrair a chave pública do arquivo .pem baixado, ou pode ter sido criado por você.
Este comando preparará o entorno da AWS para criar os componentes necessários para o Kubernetes funcionar. Dizemos qual é a Cloud utilizada, qual a zona de DNS, os tamanhos das instâncias (temos que começar com t2.small pois o Kubernetes não instalará numa t2.micro por falta de memória), quantos masters e quantos nodes teremos, quais os CIDR de cada uma das nossas AZ, qual o nome do nosso cluster, qual chave SSH utilizaremos (a chave pública será copiada automaticamente para o arquivo de authorized_keys do usuário core), qual nossa versão do Kubernetes e qual imagem utilizaremos.
Iniciando nosso cluster
Execute o seguinte comando para iniciar nosso cluster:
kops update cluster ${DOMAIN_NAME} --yes
Teremos que aguardar algum tempo até que o cluster esteja totalmente pronto e funcionando. Diversos componentes serão criados na AWS durante esse processo. Teremos ELB, hosts criados no Route53, instâncias no EC2 e muito mais. Enquanto aguardamos, gosto de rodar o comando abaixo para verificar o status:
while ! kops validate cluster ; do sleep 5 ; done
Populando o cluster com serviços standard
Instalamos o dashboard do Kubernetes e ferramentas de monitoração:
Deixe esse comando rodando e aponte seu browser para http://127.0.0.1:8001/ui. Você estará no dashboard do seu cluster Kubernetes.
Populando o cluster com serviços extras
Usaremos o gerenciador de pacotes para Kubernetes chamado Helm. Para instalá-lo,
No MAC OS-X faça:
brew install kubernetes-helm
No Linux, faça:
wget https://kubernetes-helm.storage.googleapis.com/helm-v2.2.2-linux-amd64.tar.gz
tar xvfz helm-v2.2.2-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin
Uma vez instalado, prepararemos o cluster para utilizar o Helm:
helm init
Atualize o caching do Helm com as definições mais atuais:
helm repo update
Instalamos um pacote no cluster. Como exemplo, vamos montar um Grafana, ferramenta popular de geração de gráficos, bastante usada em monitorações:
helm install stable/grafana
Siga as instruções geradas pelo comando acima para acessar o seu Grafana novinho em folha. No final, você o acessará pela senha que as instruções deram a você, com usuário admin em http://localhost:443
Para acessarmos o serviço, precisamos perguntar para a API do Kubernetes onde ele está e quais as credenciais de acesso. Utilizaremos também o KOPS para conseguir essas informações:
kops get secrets -oplaintext --type=secret kube
Para acessar o cluster sem ter que colocar no browser o endereço do nosso domínio, podemos usar assim:
No MAC OS-X:
open https://api.${DOMAIN_NAME}/
No Linux:
xdg-open https://api.${DOMAIN_NAME}/
O usuário para acesso ao painel é admin e a senha foi a conseguida no passo de get secrets.
Destruindo o cluster
Para remover totalmente seu cluster e quaisquer objetos criados para ele na AWS, execute o seguinte comando: